Earlier this week we wrote about the classic approach to the semantic web and the difficulties with that approach. While the original vision of the layer
on top of the current web, which annotates information in a way that is “understandable” by computers, is compelling; there are technical, scientific and business issues that have been difficult to address.

One of the technical
difficulties that we outlined was the bottom-up nature of the classic semantic web approach. Specifically,
each web site needs to annotate information in RDF, OWL, etc. in order for computers to be able to “understand” it.
As things stand today, there is little reason for web site owners to do that. The tools that would leverage
the annotated information do not exist and there has not been any clearly articulated business and consumer value. Which means that there is
no incentive for the sites to invest money into being compatible with the semantic web of the future.
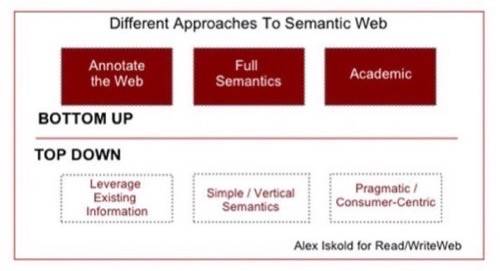
But there are alternative approaches. We will argue that a more pragmatic, top-down approach to the semantic
web not only makes sense, but is already well on the way toward becoming a reality. Many companies have been leveraging existing,
unstructured information to build vertical, semantic services. Unlike the original vision, which is rather
academic, these emergent solutions are driven by business and market potential.
In this post, we will look at the solution that we call the top-down approach to the semantic web,
because instead of requiring developers to change or augment the web, this approach leverages and builds on top of current web as-is.
Why Do We Need The Semantic Web?
The complexity of original vision of the semantic web and lack of clear consumer benefits makes the whole
project unrealistic. The simple question: Why do we need computers to understand semantics? remains largely
unanswered.

While some of us think that building AI is cool, the majority of people think that AI is a little bit silly, or perhaps even unsettling.
And they are right. AI for the sake of AI does not make any sense. If we are talking about building
intelligent machines, and if we need to spend money and energy annotating all the information in
the world for them, then there needs to be a very clear benefit.
Stated the way it is, the semantic web becomes a vision in search of a reason. What if the problem was restated
from the consumer point of view? Here is what we are really looking forward to with the semantic web:
- Spend less time searching
- Spend less time looking at things that do not matter
- Spend less time explaining what we want to computers

A consumer focus and clear benefit for businesses needs to be there in order for the semantic web
vision to be embraced by the marketplace.
What If The Problem Is Not That Hard?
If all we are trying to do is to help people improve their online experiences, perhaps
the full “understanding” of semantics by computers is not even necessary. The best online search tool today
is Google, which is an algorithm based, essentially, on statistical frequency analysis and not
semantics. Solutions that attempt to improve Google by focusing on generalized semantics have so far not been finding
it easy to do so.
The truth is that the understanding of natural language by computers is a really hard problem. We have the language
ingrained in our genes. We learn language as we grow up. We learn things iteratively. We have the chance to
clarify things when we do not understand them. None of this is easily replicated with computers.
But what if it is not even necessary to build the first generation of semantic tools? What if instead of trying to teach computers natural language, we hard-wired into computers the concepts
of everyday things like books, music, movies, restaurants, stocks and even people. Would that help us
be more productive and find things faster?
Simple Semantics: Nouns And Verbs
When we think about a book we think about handful of things – title and author, maybe genre and the year it was
published. Typically, though, we could care less about the publisher, edition and number of pages. Similarly, recipes provoke
thoughts about cuisine and ingredients, while movies make us think about the plot, director, and stars.
When we think of people, we also think about a handful of things: birthday, where do they live, how we’re related to them, etc.
The profiles found on popular social networks are great examples of simple semantics based around people:
Books, people, recipes, movies are all examples of nouns. The things that we do on the web around these
nouns, such as looking up similar books, finding more people who work for the same company, getting more
recipes from the same chef and looking up pictures of movie stars, are similar to verbs in everyday language.
These are contextual actuals that are based on the understanding of the noun.
What if semantic applications hard-wired understanding and recognition of the nouns
and then also hard-wired the verbs that make sense? We are actually well on our way
doing just that. Vertical search engines like Spock, Retrevo, ZoomInfo, the page annotating technology from Clear Forrest,
Dapper, and the Map+ extension for Firefox are just a few examples of top-down semantic web services.
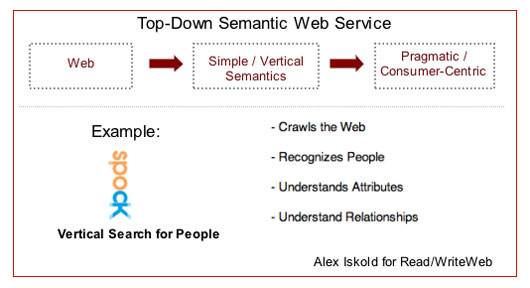
The Top-Down Semantic Web Service
The essence of a top-down semantic web service is simple – leverage existing web information,
apply specific, vertical semantic knowledge and then redeliver the results via a consumer-centric application.
Consider the vertical search engine Spock, which scans the web for information about people.
It knows how to recognize names in HTML pages and it also looks for common information about people that all people have –
birthdays, locations, marital status, etc. In addition, Spock “understands” that people relate to each other.
If you look up Bush, then Clinton will show up as a predecessor. If you look up Steve Jobs, then Bill Gates
will come up as a rival.
In other words, Spock takes simple, everyday semantics about people and applies it to the information
that already exists online. The result? A unique and useful vertical search engine for people. Further, note that Spock
does not require the information to be re-annotated in RDF and OWL. Instead, the company builds adapters that
use heuristics to get the data. The engine does not actually have full understanding of semantics about people, however.
For example, it does not know that people like different kinds
of ice cream, but it doesn’t need to. The point is that by focusing on a simple semantics, Spock is able to deliver
a useful end-user service.
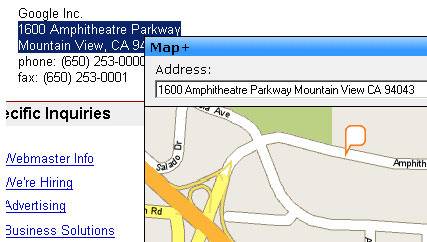
Another, much simpler, example is the Map+ add-on for Firefox. This application recognizes
addresses and provides a map popup using Yahoo! Maps. It is the simplicity of this application that
precisely conveys the power of simple semantics. The add-on “knows” what addresses look like. Sure,
sometimes it makes mistakes, but most of the time it tags addresses in online documents properly. So it leverages existing information
and then provides direct end user utility by meshing it up with Yahoo! Maps.
The Challenges Facing The Top-Down Approach
Despite being effective, the somewhat simplistic top-down approach has several problems.
First, it is not really the semantic web as it is defined, instead its a group of semantic web services
and applications that create utility by leveraging simple semantics. So the proponents of the classic approach would protest and they would be right.
Another issue is that these services do not always get semantics right because of ambiguities. Because
the recognition is algorithmic and not based on an underlying RDF representation, it is not perfect.
It seems to me that it is better to have simpler solutions that work 90% of the time than complex ones that never arrive. The key questions here are: How exactly are mistakes handled? And, is there a way for the user to correct the problem? The answers will be
left up to the individual application. In life we are used to other people being unpredictable,
but with computers, at least in theory, we expect things to work the same every time.
Yet another issue is that these simple solutions may not scale well. If the underlying unstructured
data changes can the algorithms be changed quickly enough? This is always an issue with things that sit on
top of other things without an API. Of course, if more web sites had APIs, as we have previously suggested, the top-down semantic web would be much easier and more certain.
Conclusion
While the original vision of the semantic web is grandiose and inspiring in practice it has been
difficult to achieve because of the engineering, scientific and business challenges. The lack of specific
and simple consumer focus makes it mostly an academic exercise. In the mean time, existing data is being leveraged by applying simple heuristics and making assumptions about particular verticals.
What we have dubbed top-down semantic web applications have been appearing online and improving
end user experiences by leveraging semantics to deliver real, tangible services.
Will the bottom-up semantic web ever happen? Possibly. But, at the moment the precise path to get there is not quite clear.
In the mean time, we can all enjoy better online experience and get to where we need to go faster thanks to
simple top-down semantic web services.

















