A few months ago we linked to Toma Kova?i?’s overview of text extraction algorithms. Now Kova?i? has posted an evaluation of several text extraction algorithms and services, including Boilerpipe, NCleaner, the Python and Node.js versions of Readability and the Extractiv API.

To conduct his evaluations, Kova?i? used the cleaneval dataset, which includes 681 documents, and a Google News dataset with 621 documents harvested by the authors of Boilerpipe.
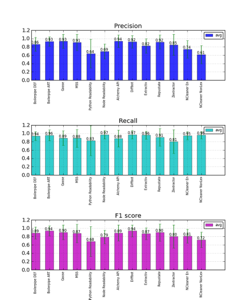
Metric for the Google News data set
A few notes:
- NCleaner did better on its own Cleaneval data set than it did on the Google News data set, but Boilerpipe did well on both sets.
- Kova?i?’ was surprised by Readability’s poor performance, and notes the discrepancy between the two ports. He thinks the original JavaScript version may do better.
- The commercial APIs had the most consistent results.

















