It took a little longer than expected, but the Apache Software Foundation has announced the general availability of Apache Hadoop 2.0 yesterday, which will ultimately be an elephant-sized step in how Hadoop is used for managing big data collections.
The biggest change to Apache Hadoop 2.2.0, the first generally available version of the 2._x_ series, is the update to the MapReduce framework to Apache YARN, also known as MapReduce 2.0. MapReduce is a big feature in Hadoop—the batch processor that lines up search jobs that go into the Hadoop distributed file system (HDFS) to pull out useful information. In the previous version of MapReduce, jobs could only be done one at a time, in batches, because that’s how the Java-based MapReduce tool worked.
See also: Hadoop: What It Is And How It Works
With the available update, MapReduce 2.0 will enable multiple search tools to hit the data within the HDFS storage system at the same time.
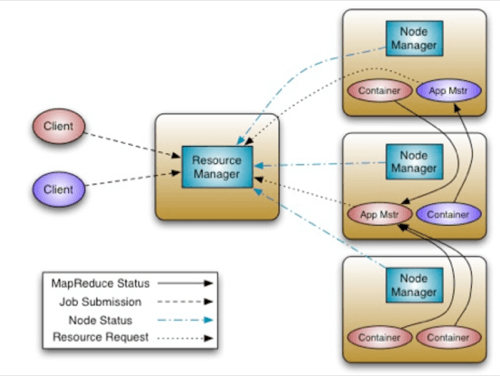
What YARN does is divide the functionality of MapReduce even further, breaking the two major responsibilities of the MapReduce JobTracker component—resource management and job scheduling/monitoring—into separate applications: a global ResourceManager and per-application ApplicationMaster.
Splitting up these functions provides a more powerful way to manage a Hadoop cluster’s resources than the current MapReduce systems can handle. It manages resources similar to the way an operating system handles jobs, which means no more one-at-a-time limitation.
With MapReduce 2.0, developers can now build apps directly within Hadoop, instead of bolting them on from the outside, as many third-party vendor tools have had to do in Hadoop 1.0. This essentially will establish Hadoop 2.0 as a platform into which developers can create applications that will search for an manipulate data far more efficiently.
While YARN is the biggest change in the new version of Hadoop, there are some nice changes in the HDFS side of the Hadoop, too, including high availability for HDFS, HDFS snapshots, and support for the NFSv3 filesystem to access data in HDFS, if need be.
Also, Hadoop 2.2 is now officially supported on Microsoft Windows, which will no doubt stir up interest from companies committed to Microsoft-only platforms.
There will no doubt be growing pains with Hadoop as companies migrate the new release, but the fundamental changes to the MapReduce framework will mean even more usefulness for Hadoop in big-data scenarios moving forward. Expect a lot of new tools that will capitalize on the new capabilities in YARN, and soon.
YARN image courtesy of Hortonworks.

















