“Big Data” is the technology that is supposedly reshaping the data center. Sure, the data center isn’t as fun a topic as the iPad, but without the data center supplying the cloud with apps, iPads wouldn’t nearly as much fun either. Big Data is also the nucleus of a new and growing industry, injecting a much-needed shot of adrenaline in the business end of computing. It must be important; in March President Obama made it a $200 million line item in the U.S. Federal Budget. But what the heck is Big Data?
With hundreds of millions of taxpayer dollars behind it, with billions in capital and operating expenditures invested in it, and with a good chunk of ReadWriteWeb’s space and time devoted to it, well, you’d hope that we all pretty much knew what Big Data actually was. But a wealth of new evidence, including an Oracle study reported by RWW’s Brian Proffitt last week, a CapGemini survey uncovered by Sharon Fisher also last week, and now a Harris Interactive survey commissioned by SAP, all indicate a disturbing trend: Both businesses and governments may be throwing money at whatever they may think Big Data happens to be. And those understandings may depend on who their suppliers are, who’s marketing the concept to them and how far back they began investigating the issue.
That even the companies investing in Big Data have a relatively poor understanding of it may be blamed only partly on marketing. To date, the Web has done a less-than-stellar job at explaining what Big Data is all about. “The reality is, when I looked at these survey results, the first thing I said was, wow. We still don’t have people who have a common definition of Big Data, which is a big problem,” said Steve Lucas, executive vice president for business analytics at SAP.
The $500 Million Pyramid
The issue is that many companies are just now facing the end of the evolutionary road for traditional databases, especially now that accessibility through mobile apps by thousands of simultaneous users has become a mandate. The Hadoop framework, which emerged from an open source project out of Yahoo and has become its own commercial industry, presented the first viable solution. But Big Data is so foreign to the understanding customers have already had about their own data centers, that it’s no wonder surveys are finding their strategies spinning off in various directions.
“What I found surprising about the survey results was that 18% of small and medium-sized businesses under $500 million [in revenue] per year think of Big Data as social- and machine-generated,” Lucas continued. “Smaller companies are dealing with large numbers of transactions from their Web presence, with mobile purchases presenting challenges for them. Larger companies have infrastructure to deal with that. So they’re focused … on things like machine-generated data, cell phones, devices, sensors, things like that, as well as social data.”
Snap Judgment
Harris asked 154 C-level executives from U.S.-based multi-national companies last April a series of questions, one of them being to simply pick the definition of “Big Data” that most closely resembled their own strategies. The results were all over the map. While 28% of respondents agreed with “Massive growth of transaction data” (the notion that data is getting bigger) as most like their own concepts, 24% agreed with “New technologies designed to address the volume, variety, and velocity challenges of big data” (the notion that database systems are getting more complex). Some 19% agreed with the “requirement to store and archive data for regulatory and compliance,” 18% agreed with the “explosion of new data sources,” while 11% stuck with “Other.”
All of these definition choices seem to strike a common theme that databases are evolving beyond the ability of our current technology to make sense of it all. But when executives were asked questions that would point to a strategy for tackling this problem, the results were just as mixed.
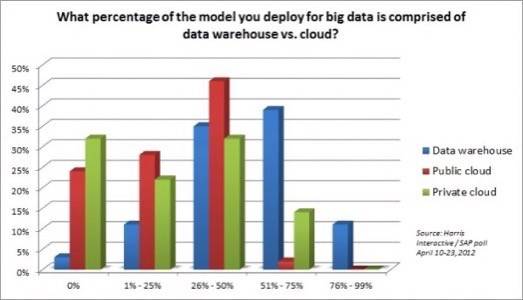
When SAP’s Lucas drilled down further, however, he noticed the mixture does tend to tip toward one side or the other, with the fulcrum being the $500 million revenue mark. Companies below that mark (about 60% of total respondents), Lucas found, are concentrating on the idea that Big Data is being generated by Twitter and social feeds. Companies above that mark may already have a handle on social data, and are concentrating on the problem of the wealth of data generated by the new mobile apps they’re using to connect with their customers – apps with which the smaller companies aren’t too familiar yet.
“That slider scale may change the definition above or below that $500 million in revenue mark for the company based on their infrastructure, their investment, and their priorities,” Lucas said. “They also pointed out that the cloud is a critical part of their Big Data strategy. I took that as a big priority.”
Final Jeopardy
So what’s the right answer? Here is an explanation of “Big Data” that, I believe, applies to anyone and everyone:
Database technologies have become bound by business logic that fails to scale up. This logic uses inefficient methods for accessing and manipulating data. But those inefficiencies were always masked by the increasing speed and capability of hardware, coupled with the declining price of storage. Sure, it was inefficient, but up until about 2007, nobody really noticed or cared.
The inefficiencies were finally brought into the open when new applications found new and practical uses for extrapolating important results (often the analytical kind) from large amounts of data. The methods we’d always used for traditional database systems could not scale up. Big Data technologies were created to enable applications that could scale up, but more to the point, they addressed the inefficiencies that had been in our systems for the past 30 years – inefficiencies that had little to do with size or scale but rather with laziness, our preference to postpone the unpleasant details until they really became bothersome.
Essentially, Big Data tools address the way large quantities of data are stored, accessed and presented for manipulation or analysis. They do replace something in the traditional database world – at the very least, the storage system (Hadoop), but they may also replace the access methodology.

















