



Latest News

Cat people rejoice – new feline gore fest lets you get your claws into some bloodthirsty unicorns
Sometimes I look back a what I have just written and wonder if I am in some kind of fever dream. That title for example. Don’t tell me ChatGPT could ever come up with that. Just don’t. The fever dream continues as I watch the amazing new trailer for Cat ‘em-up, Gori: Cuddly Carnage. As…


















Artificial Intelligence

Google AI Gemini to receive real-time responses in app
Ali ReesTech journalist

Cryptocurrency

Binance founder faces 36-month prison term for violating US laws
In a startling development, US prosecutors are pushing for a 36-month prison term for Changpeng Zhao, the founder of cryptocurrency exchange Binance, according to a court filing on Tuesday. Zhao, who stepped down as CEO but retains majority ownership of...
Radek ZielinskiTech Journalist



Entertainment


Technology

US Senate passes bill banning TikTok unless it divest
The United States Senate has passed a bill that requires TikTok, a Chinese-based company, to divest or face a ban on American shores. ByteDance, the owner of the viral video social media platform, has been continuously scrutinized by U.S. politicians...
Brian-Damien MorganFeatures Writer

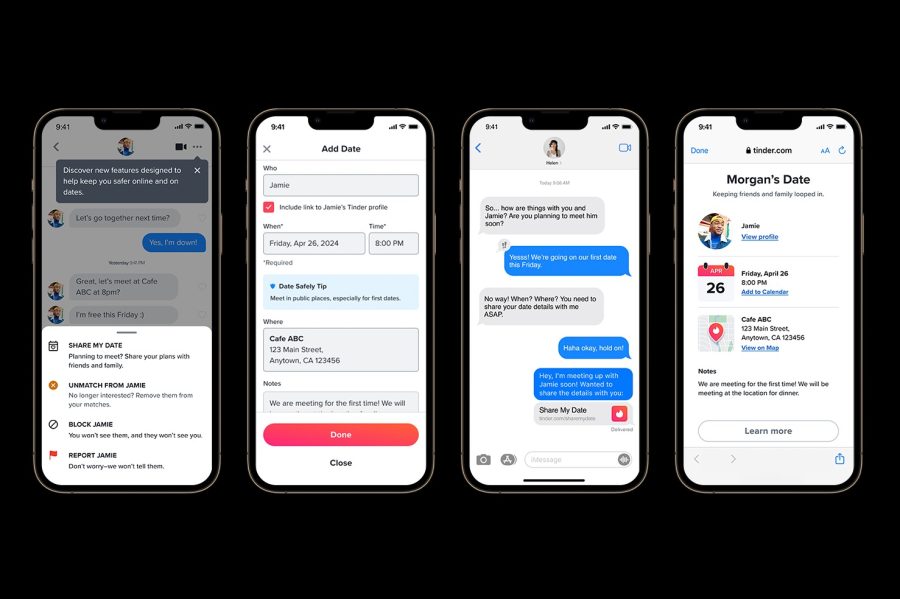
Tinder’s new ‘Share My Date’ feature explained
Ali ReesTech journalist

AR / VR
Smartphones


We are an award-winning tech website where trusted research and expert knowledge come together
Since 2003, we have helped millions of people learn how to solve tech problems large and small. We work with credentialed experts, a team of trained researchers, and a devoted community to create the most reliable, comprehensive and delightful content on the Internet.
1M
Monthly Readers1.4M
Followers on X35K
ArticlesTrusted
for 20 years5000+
research hrs100+
EXPERT CONTRIBUTORSPopular Topics
Get the biggest tech headlines of the day delivered to your inbox
Explore the latest in tech with our Tech News. We cut through the noise for concise, relevant updates, keeping you informed about the rapidly evolving tech landscape with curated content that separates signal from noise.
Explore tech impact in In-Depth Stories. Narrative data journalism offers comprehensive analyses, revealing stories behind data. Understand industry trends for a deeper perspective on tech's intricate relationships with society.
Empower decisions with Expert Reviews, merging industry expertise and insightful analysis. Delve into tech intricacies, get the best deals, and stay ahead with our trustworthy guide to navigating the ever-changing tech market.