











There aren’t many redeeming qualities for big data other than its bigness. Although we may think giant SQL data tables have become unwieldy, they’re not the cause of the “data obesity” problem that afflicts large enterprises. More big data is made up of raw text logs, event streams exuding from admin scripts, and bits of data sifted from other event streams.

While Hadoop may be faster at processing giant pooled partitions of data in parallel, it first has to make some sort of sense. Up to now, the way database admins have accomplished this is by writing parsers, often in Perl or Python or Ruby. Field by field, data elements are tweezed out of the huge stream and inserted into a Hive table – Hadoop’s format for re-interpreting large streams as tables using a SQL-like language. Alternately, admins have learned Hadoop’s data analysis language, called Pig, to create parsing jobs that can be run in parallel in Hadoop clusters.
It’s not easy going either way. Today, as part of the premiere of Hortonworks Data Platform for Hadoop in the cloud, community member Informatica announced it’s giving parser script writers a well-deserved break. A visual parsing tool called HParser is being added to HDP.
“What HParser does is allow companies to more efficiently extract meaning out of that data, especially when that data is unstructured,” states Juan Carlos Soto, senior vice president and general manager of Informatica, in an interview with RWW. “If the data is schema-less, how do you extract meaning from it, put it in some kind of structure that is easier for you to continue processing in your Hadoop environment? That’s typically a parsing problem.”

HParser leverages existing Informatica software assets for use with Hadoop data, creating a visual environment for admins to lasso examples of elements of data that need to be extracted, using a sample of the existing data set. From these visual cues, HParser generates parsing instructions, which are then run as processes in parallel on each node in the Hadoop data cluster.
Workflow showing how Informatica HParser parses and handles Hadoop data. [Courtesy Informatica]
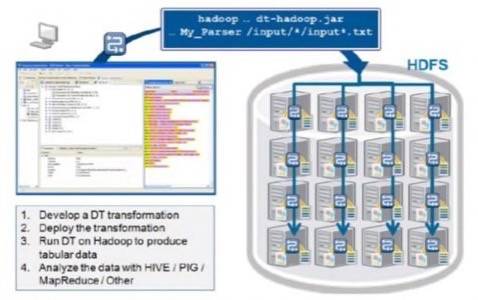
“Positional parsing [like this] is one of the easier use cases,” Soto explains. “Even in that case, it’s nice to be able to highlight the data – like the fifth field of every third row – and have it automatically generate the parsing code through the visual designer. But a lot of the data is also encoded in XML or JSON, and that’s a little bit more complicated… So we provide out-of-the-box support for those very commonly used formats in big data processing.”
Automatically supported formats include: HL7 for the healthcare industry’s HIPPA regulatory compliance; fixed-format quotes of trading transactions on stocks and commodities exchanges; the international SWIFT payment system format; and the call detail record (CDR) format, called ASN.1 used by cell towers and call tracking equipment for the nation’s telcos.
“Every vendor of network equipment might have a slight, vendor-specific variation on that format,” the SVP remarks. “Using a tool like ours and leveraging our expertise in this area means that [admins] can quickly get up to speed on the current standards.”
Panel discussion with Ronen Schwartz, VP for B2B products, Informatica; and Karl Van Den Bergh, VP for products and alliances, Jaspersoft
The free Community Edition includes documentation demonstrating how to make a MapReduce call for HParser to extract the input and place the output. That call is then replicated among the nodes handling Hadoop data in parallel. The free version also supports XML and JSON out of the box. The commercial edition licenses libraries for handling various industry standard data formats, the prices for which Soto tells us are still being worked out.
“We believe that big data is real,” pronounces Informatica’s Juan Carlos Soto, “and it’s here to stay for the enterprise. Second to human resources, data is the most valuable asset any enterprise has. It’s part of our broader vision to increase the return on data for any enterprise. We’ve done that for traditional data warehousing-style analytics, and now with this explosion of different kinds of unstructured data, the same needs apply for the enterprise. What Hortonworks and the other vendors are doing to bring big data processing more broadly to enterprises, we think, will help companies get more return on their data.”



















