There is little doubt that RSS is a disruptive, game-changing technology. The so called Really Simple Syndication (previously also called Rich Site Summary and RDF Site Summary), has powered a fundamentally new way to deliver and consume web content. Before RSS, users had to visit individual web sites to find out what was new. Today, news is delivered via RSS directly to web browsers, desktops and aggregators. With RSS, the dynamics of the web changed into an on-demand medium.

RSS usage has since spread beyond simple news delivery. Companies like de.licio.us, Flickr and YouTube added another dimension to RSS – i.e. they made it an integral part of the Social Web (social networking, photos, video, etc). Also Google built Google Base, its Craigslist competitor, entirely on RSS. Other companies too are beginning to extend RSS, sometimes with proprietary extensions.
In short, because of RSS ubiquity it is now a very attractive delivery medium for all kinds of content. However because the basic format is simple and primitive, there is no way to encode semantics without building an extension. So in this post, we look at RSS today and ask if RSS is evolving into a tool for delivering complex, semantically rich information.
Brief History of RSS
RSS is an XML-based language and its early roots can be traced to back to 1995, to Apple Labs and then slightly later to Netscape, Userland Software and Microsoft. The first major use of RSS was in 1999 when it was integrated into the My Netscape portal. So RSS is not a new kid on the block, in fact it was around way before the new Social Web came about. So why did it not take off earlier? It appears to have been misunderstood and de-emphasized by AOL, and was downplayed after the Netscape acquisition.
RSS survived mainly because of one man’s heavy-lifting – Dave Winer. Dave authored RSS 0.91, RSS 0.92 and then the widely used RSS 2.0 specification. Over the years he has drummed the beat of RSS on his blog and every corner of the web, until it got adopted by companies such as Microsoft and Yahoo. [Ed: there were also heated format wars during this time, with RSS 1.0 and then ATOM, but we won’t re-hash those here!]
RSS in a Nutshell
RSS is rather simple language to describe the latest headlines (or the full content of articles). The following explanation of RSS is based on the RSS 2.0 format, but other formats are similar. Here is a sample of what it looks like:
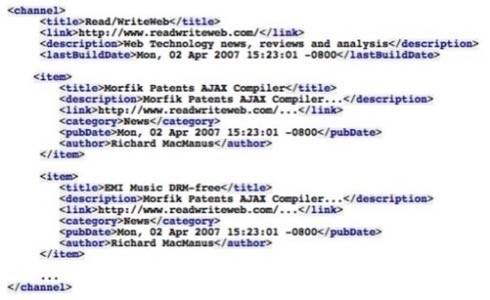
Each RSS file consists of items delivered in a single channel. Each item has a title, a link and a description (attributes). The on-demand aspect of RSS is enabled by two timestamps – the lastBuildDate in the channel indicates the last time this channel changed, while the pubDate of the item indicates when the item was published. RSS aggregators (a.k.a. RSS readers) take advantage of these timestamps to decide when new content is available.
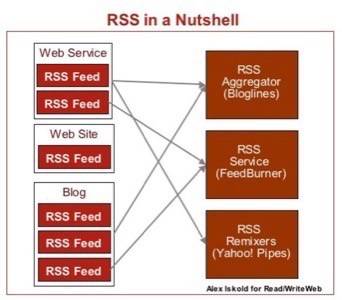
The old web was a pure pull medium, because users had to visit each web site in order to find out what (if anything) had changed. However, businesses and advertisers in particular love push technologies – where content is delivered to the user when it becomes available. RSS is an interesting mix between the two extremes, neither of which could actually work in our information-overloaded and advertising-saturated world. RSS is basically a filtered push – the user subscribes (pulls in) to channels that he/she likes, and after that content is delivered automatically.
RSS – Beyond the Distribution Medium
So today RSS is a great distribution medium. Why? Because it has become ubiquitous. If you are an online business with customers and you do not utilize RSS, then you are simply missing out. Smart companies are leveraging blogs, photos, video, podcasts to stay in touch with customers daily. Other services, like del.icio.us (owned by Yahoo), allow users to publish and subscribe to feeds, enabling powerful social networks outside the website.
The ubiquity of RSS is so powerful that publishers want to deliver more and more content to users via RSS. But the problem is that basic RSS cannot be used to deliver structured information.
Lets look at a specific example. Suppose your bank wants to deliver you statements in RSS instead of email. However if you use RSS as it is today, then the bank statements would need to be encoded in HTML – meaning no financial application would be able to manipulate the data. When your Quicken software connects to the bank, the information gets downloaded in a structured format. But with RSS, it is simply not possible currently – because there is no way to describe bank transactions using standard RSS.
Why this matters
At first glance this might not make much sense. Why do we care about RSS having structure? Because structured RSS holds the promise of information portability. Going back to the bank statement example, it would be great if the statement also can be taken as an input by a financial application of your choice. Since we are moving our desktops online – e.g. the trend of Web Office suites – the formats that we used in the Windows age are not going to work well. We need something lighter and more portable to carry our information around – hence XML and RSS.
Note that businesses are probably the most interested party here, because to a business a loss of structure leads to loss of meaning, loss of trail and ultimately the loss of customers.
Extending RSS
To extend RSS basically means to add a custom tag. For example, Google Base currently has 148 attributes that it recommends to add to RSS. Here are some examples starting with the letter ‘a’: age, actor, agent, apparel type, artist. These are everyday concepts that might come handy in classifieds and other aspects of life. All of these tags allow Google Base to make RSS structured, whilst preserving its basic capability.
Similarly, FeedBurner inserts proprietary attributes into their RSS feeds. This is done purely for house keeping purposes, because only FeedBurner’s engine is meant to process these attributes.
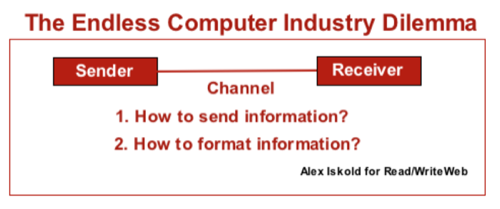
The main problem with extending RSS is agreeing on what things mean. In the case of FeedBurner it is not critical, but in the case of Google Base it is much more important. In order for RSS extensions to work, the second piece of the old technology dilemma needs to be solved. There needs to be a common format for communicating data between applications:

Conclusion
Purists, myself included, would argue that using RSS for the delivery of complex content is a hack. After all, what does a news format have to do with semantics? But technologies do not evolve in a pure way. Some things catch on and succeed, and become widely adopted. The fact is that RSS is becoming a pervasive on-demand technology, which outweighs the fact that it was never meant to be the semantic agent of the web. But even from a purist’s perspective, there may not be much to pick at – RSS is just another XML-language and in that respect it is as good as any other flavor of XML.
So will RSS become more than it is today? Will it be able to solve the second piece of the old technology industry puzzle – the common format? As usual, only time will tell. However RSS does look like a strong front runner at this point, as we do not have a lot of attractive, simple and widespread alternatives. But again, who knows, technology is not a predictable thing.
Do you think RSS will expand beyond what it is today? What real world things are you are seeing that hint at RSS being used in more ways?

















