The long awaited and ultra-ambitious Encyclopedia of Life finally came online on Tuesday, but no sooner did it spring to life than, like an infant version of one of the species it catalogs, it fell flat on its face. Apparently underestimating the interest that the site would generate, its servers buckled under the load and yesterday, the old teaser site was put back online. Today, the EOL’s first 30,000 pages are back up, though still noticeably slow.

Announced last spring, the Encyclopedia of Life is a non-profit project aiming to create an online database of all 1.8 million species known to science. The project is expected to take 10 years to complete and cost in excess of $100 million. It is so far funded via grants from the MacArthur and Sloan Foundations.
Each species in the EOL gets its own page, complete with descriptive text, images, maps, diagrams, and other multimedia. For now, the project is drawing on previously existing databases of scientific information, which are distilled and validated by independent experts. Later in the year, the EOL will begin to accept submissions from visitors, but information will be authenticated by an expert “curator” before being added to the public encyclopedia page.
It is this transparency and scientific oversight that the EOL’s creators hope allow the site to be looked at by the academic community as a credible source of scientific information. In fact, one of the EOL’s goals is to create teaching materials based around the site’s content.
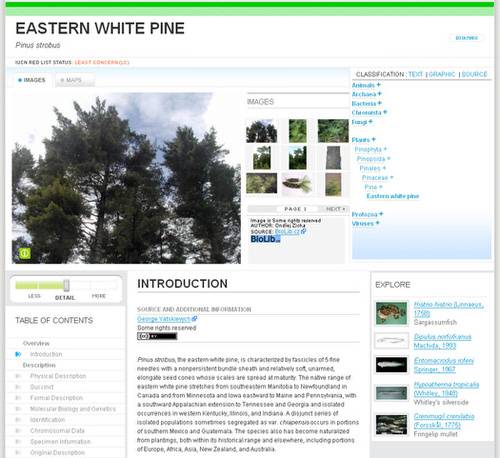
So far the encyclopedia has 30,000 pages up, with a small set of exemplar pages that serve as examples of the kind of depth of information that the EOL hopes all pages will one day have.
Being a web encyclopedia, the EOL will unavoidably be compared to Wikipedia. Since none of us at RWW are biologists, it is hard to compare the two based on quality of information. But for the two or three exemplar pages we compared to their Wikipedia equivalents, there didn’t seem to be a great deal more volume of information on the EOL than on Wikipedia. The quality of the info is an altogether different matter.
In addition to accepting user submissions the EOL also plans a set of APIs that will allow developers to access and manipulate the EOL data. We just hope they get their server woes sorted before the APIs are released later this year.
The EOL is a wildly ambitious project, and whether the result is more accurate than Wikipedia is irrelevant. Collecting and cataloging the scope and breadth of human knowledge, especially at a time when our climate and biodiversity faces potentially drastic changes, is an admirable task. The EOL, when completed (in so far as it ever can be completed) will be a very helpful tool for the scientific and academic community.

















