











Today’s Web has terabytes of information available to humans, but hidden
from computers. It is a paradox that information is stuck inside HTML pages, formatted in
esoteric ways that are difficult for machines to process. The so called Web 3.0, which is
likely to be a pre-cursor of the real semantic web, is going to change this. What
we mean by ‘Web 3.0’ is that major web sites are going to be transformed into web
services – and will effectively expose their information to the world.

The transformation will happen in one of two ways. Some web sites will follow the
example of Amazon, del.icio.us and Flickr and will offer their information via a REST
API. Others will try to keep their information proprietary, but it will be opened via
mashups created using services like Dapper, Teqlo and Yahoo! Pipes.
The net effect will be that unstructured information will give way to structured
information – paving the road to more intelligent computing. In this post we will
look at how this important transformation is taking place already and how it is likely to
evolve.
The Amazon E-Commerce API – open access to Amazon’s catalog
We have written here before
about Amazon’s visionary WebOS strategy. The Seattle web giant is reinventing itself by
exposing its own infrastructure via a set of elegant APIs. One of the first web services
opened up by Amazon was the
E-Commerce service. This service opens access to the majority of items in Amazon’s
product catalog. The API is quite rich, allowing manipulation of users, wish lists and
shopping carts. However its essence is the ability to lookup Amazon’s products.

Why has Amazon offered this service completely free? Because most applications built
on top of this service drive traffic back to Amazon (each item returned by the service
contains the Amazon URL). In other words, with the E-Commerce service Amazon enabled
others to build ways to access Amazon’s inventory. As a result many companies have come
up with creative ways of leveraging Amazon’s information – you can read about these
successes in one of our previous posts.
The rise of the API culture
The web 2.0 poster child, del.icio.us, is also famous as one
of the first companies to open a subset of its web site functionality via an API. Many services followed, giving rise to a
true API culture. John Musser over at programmableweb has been tirelessly cataloging
APIs and Mashups that use them. This page shows almost 400 APIs
organized by category, which is an impressive number. However, only a fraction of those
APIs are opening up information – most focus on manipulating the service itself.
This is an important distinction to understand in the context of this article.

The del.icio.us API offering today is different from Amazon’s one, because it does
not open the del.icio.us database to the world. What it does do is allow
authorized mashups to manipulate the user information stored in del.icio.us. For example,
an application may add a post, or update a tag, programmatically. However, there is no
way to ask del.icio.us, via API, what URLs have been posted to it or what has been tagged
with the tag web 2.0 across the entire del.icio.us database. These questions are
easy to answer via the web site, but not via current API.
Standardized URLs – the API without an API
Despite the fact that there is no direct API (into the database), many companies have
managed to leverage the information stored in del.icio.us. Here are some
examples…
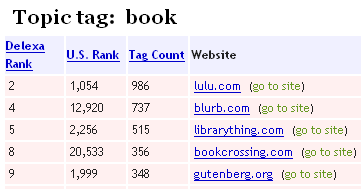
Delexa is an interesting and useful mashup that
uses del.icio.us to categorize Alexa sites. For example, here are the popular sites tagged with the word
book:
Another web site called similicio.ususes
del.icio.us to recommend similar sites. For example,
here are the sites that it thinks are related to Read/WriteWeb.
So how do these services get around the fact that there is no API? The answer is that
they leverage standardized URLs and a technique called Web scraping. Let’s understand how
this works. In del.icio.us, for example, all URLs that have the tag book can be
found under the URL http://del.icio.us/tag/book; all URLs tagged with
the tag movie are at http://del.icio.us/tag/movie; and so on. The
structure of this URL is always the same: http://del.icio.us/tag[TAG].
So given any tag, a computer program can fetch the page that contains the list of sites
tagged with it. Once the page is fetched, the program can now perform the scraping – the
extraction of the necessary information from the page.
How Web Scraping Works
Web Scraping is essentially reverse engineering of HTML pages. It can also be thought
of as parsing out chunks of information from a page. Web pages are coded in HTML, which
uses a tree-like structure to represent the information. The actual data is mingled with
layout and rendering information and is not readily available to a computer. Scrapers are
the programs that “know” how to get the data back from a given HTML page. They work by
learning the details of the particular markup and figuring out where the actual data is.
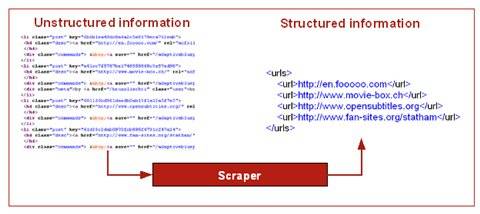
For example, in the illustration below the scraper extracts URLs from the del.icio.us
page. By applying such a scraper, it is possible to discover what URLs are tagged with
any given tag.
Dapper, Teqlo, Yahoo! Pipes – the upcoming scraping technologies
We recently covered Yahoo!
Pipes, a new app from Yahoo! focused on remixing RSS feeds. Another similar
technology, Teqlo, has recently launched. It focuses
on letting people create mashups and widgets from web services and rss. Before both of
these, Dapper launched a generic scraping service
for any web site. Dapper is an interesting technology that facilitates the scraping of
the web pages, using a visual interface.

It works by letting the developer define a few sample pages and then helping her
denote similar information using a marker. This looks simple, but behind the scenes
Dapper uses a non-trivial tree-matching algorithm to accomplish this task. Once the user
defines similar pieces of information on the page, Dapper allows the user to make it into
a field. By repeating the process with other information on the page, the developer is
able to effectively define a query that turns an unstructured page into a set of
structured records.
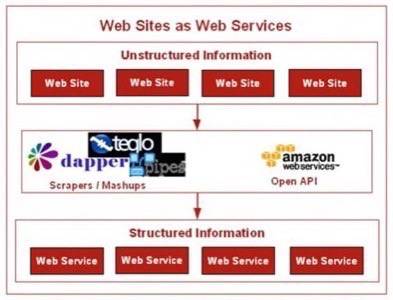
The net effect – Web Sites become Web Services
Here is an illustration of the net effect of apps like Dapper and Teqlo:
So bringing together Open APIs (like the Amazon E-Commerce service) and
scraping/mashup technologies, gives us a way to treat any web site as a web service
that exposes its information. The information, or to be more exact the
data, becomes open. In turn, this enables software to take advantage of
this information collectively. With that, the Web truly becomes a database that can be
queried and remixed.
This sounds great, but is this legal?
Scraping technologies are actually fairly questionable. In a way, they can be
perceived as stealing the information owned by a web site. The whole issue is complicated
because it is unclear where copy/paste ends and scraping begins. It is okay for people to
copy and save the information from web pages, but it might not be legal to have software
do this automatically. But scraping of the page and then offering a service that
leverages the information without crediting the original source, is unlikely to be
legal.
But it does not seem that scraping is going to stop. Just like legal issues with
Napster did not stop people from writing peer-to-peer sharing software, or the more
recent YouTube
lawsuit is not likely to stop people from posting copyrighted videos. Information
that seems to be free is perceived as being free.
The opportunities that will come after the web has been turned into a database are
just too exciting to pass up. So if conversion is going to take place anyway, would it
not be better to rethink how to do this in a consistent way?
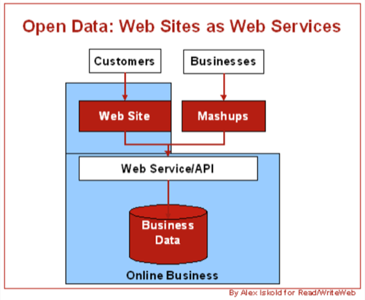
Why Web Sites should offer Web Services
There are several good reasons why Web Sites (online retailers in particular), should
think about offering an API. The most important reason is control. Having an API will
make scrapers unnecessary, but it will also allow tracking of who is using the data – as
well as how and why. Like Amazon, sites can do this in a way that fosters affiliates and
drives the traffic back to their sites.
The old perception is that closed data is a competitive advantage. The new reality is
that open data is a competitive advantage. The likely solution then is to stop
worrying about protecting information and instead start charging for it, by offering an
API. Having a small fee per API call (think Amazon Web Services) is likely to be
acceptable, since the cost for any given subscriber of the service is not going to be
high. But there is a big opportunity to make money on volume. This is what Amazon is
betting on with their Web
Services strategy and it is probably a good bet.
Conclusion
As more and more of the Web is becoming remixable, the entire system is turning into
both a platform and the database. Yet, such transformations are never smooth. For one,
scalability is a big issue. And of course legal aspects are never simple.
But it is not a question of if web sites become web services, but when
and how. APIs are a more controlled, cleaner and altogether preferred way of
becoming a web service. However, when APIs are not avaliable or sufficient, scraping is
bound to continue and expand. As always, time will be best judge; but in the meanwhile we
turn to you for feedback and stories about how your businesses are preparing for
‘web 3.0’.




















