Perhaps the biggest trend in enterprise computing is driven by a host of very small things. That is, Big Data, a terrible term used to describe the exploding volumes, variety and velocity of data, is largely the result of small devices, whether Internet of Things-style sensors or mobile devices.
If 2014 was the year that enterprises desperately tried to take off the Big Data training wheels, 2015 will be the year they succeed. Ironically, this won’t be because they master the intricacies of Hadoop and Spark. Instead, it will be because 2015 will be the year we stop trying to make every data problem into a Hadoop problem and instead use the right tool for the job.
No, You Don’t Have A Big Data Problem
One of the biggest shifts in enterprise computing is Docker and the rise of containers, but it pales in comparison to the potential impact of Big Data. As SnapLogic’s Darren Cunninhgam stresses, pretty much every significant enterprise trend ultimately comes back to data:
@mjasay data, data, data. Big, small, fast, slow, analytics, integration, discovery, prep, Data Nerds, Data Scientists. Data Eats World.
— Darren Cunningham (@dcunni) December 22, 2014
The problem, however, is that we’re far better at talking about data than we are at putting it to use. Back in 2013 I pointed out that while everyone knew they needed to be doing big things with Big Data, few actually understood how.
A year later, this hasn’t changed much.
As Gartner and others have pointed out, most companies still aren’t doing much with their data. For some it’s a matter of complexity: the (mostly) open-source tools remain too difficult for any but the best-paid data scientists to use.
But for many others it’s a continued misunderstanding of what Big Data is. For example, Matt Hunt, Bloomberg’s head of open source R&D, is spot on when he declares:
At Bloomberg that we don’t have a big data problem. What we have is a ‘medium data’ problem—and so does everyone else…. ‘Medium data’ refers to data sets that are too large to fit on a single machine but don’t require enormous clusters of thousands of them: high terabytes, not petabytes.
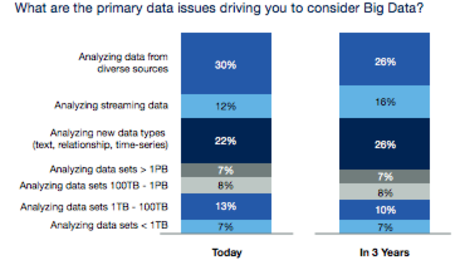
Petabytes make the news, but terabytes are what most companies actually need to manage, something an earlier NewVantage Partners survey of IT executives uncovered. A mere 28% thought their biggest challenges with Big Data had anything to do with high volumes of data. Far more were concerned with the variety and velocity of data.
This remains true as we head into 2015.
Many companies struggle because they keep trying to force Hadoop to fit their data, when it’s often the wrong tool for these “medium data” applications. I thought we had learned this in 2014. I was wrong.
2015: Big Data Gets Little
Given the importance of the Internet of Things and mobile, we’re simply not going to be able to maintain this blinding fetish for high-volume data tools. Will Hadoop play a significant part in taming IoT data? Of course.
Mike Olson, co-founder of Cloudera, says it this way:
The big opportunity for a new generation of database technology is not to go disrupt the existing OLTP or OLAP markets. It’s to unlock analytic power against new data flows, data that was never before available, to understand things about the world that we could never now before…. [A] new market and a new opportunity in Big Data—driven substantially by [the Internet of Things]—creates huge opportunities for a new class of technologies.
But Hadoop, while ideal for processing huge volumes of data, is inadequate for analyzing that data in real time. To tackle Internet of Things data effectively, NoSQL databases are a critical complement to Hadoop, making it possible to respond to real-time data.
Given the ever-changing nature of Internet of Things data (new sensors, new data types, etc.), such NoSQL databases are essential, as Machina Research posits:
Data generated from an exponentially growing number of diverse sensors, devices, applications, and things will be accompanied by a growing diversity in the structure and scale of that data—and more and more sources of additional data ranging from data sourced from corporate systems to crowdsourced data will need to be combined with this data.
A lot of the Big Data work thus far has been a mixture of Hadoop and relational database systems, or RDBMSes—which, as I’ve noted, are not always ideal. While some stick with RDBMS because, as Gartner notes, “one of the most powerful forces in DBMS is inertia,” the hard truth is that the Internet of Things and other mobile applications are forcing a change in how we think about and interact with our data.
In 2015, more Big Data pilots will move into production in tandem with a shift from stolid enterprise data warehouses to agile Hadoop, and from rigid RDBMS to more flexible NoSQL. The driving force will be the Internet of Things.
Image courtesy of Shutterstock