Not only is most Big Data infrastructure open source, but it’s also better, on average, than proprietary software. While the average Java project boasts an acceptable 2.72 defect density rate (defects per 1,000 lines of code), roughly 62% of the Big Data projects scanned by Coverity were even better with lower DDRs.
See also: Why Your Company Needs To Write More Open-Source Software
Not content to rest on their high-quality laurels, Big Data’s open source elite have significantly improved code quality since last year, according to a new report released by Coverity. Pity the poor proprietary vendors that have tried to keep pace with open source innovation in Big Data infrastructure.
Bigger … And Better
It’s no secret that open source dominates Big Data software. In fact, open source dominates all infrastructure software today, as Cloudera co-founder Mike Olson declares:
[For years we’ve witnessed] a stunning and irreversible trend in enterprise infrastructure. If you’re operating a data center, you’re almost certainly using an open source operating system, database, middleware and other plumbing. No dominant platform-level software infrastructure has emerged in the last ten years in closed-source, proprietary form.
Part of the reason is that developers increasingly rule the enterprise, and want the speed and flexibility that open source affords.
But part of it comes down to rising trust in the quality of open-source software.
On average, open-source software now exceeds proprietary software code quality, according to a 2013 Coverity report analyzing thousands of open source and proprietary code bases. And while open source’s Big Data elite still have a ways to go—a DDR of 1.0 or less is considered industry standard for good quality, with Linux coming in at 1.0 and most open source C/C++ projects averaging a .59 DDR—it’s impressive that as they grow they keep getting better.
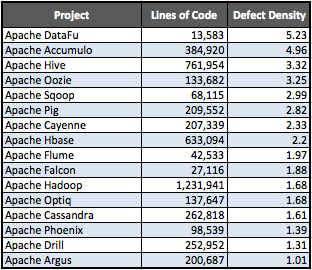
- Since the 2013 Coverity scan, Hadoop has improved from a 1.71 defect density rate to 1.67, despite adding hundreds of thousands of lines of code. Significantly, this improved DDR involved squashing a number of concurrent data access violations, null pointer dereferences and resource leaks: HBase added 200,000 lines of code yet lowered its DDR to 2.22 (from 2.33); and
- Cassandra dropped to a DDDR of 1.61 from 1.95. As with Hadoop, this has involved eliminating a range of null pointer dereferences and resource leaks.
While it would be interesting to see these Big Data projects tackling the volume of defects, it’s even more impressive how these communities have taken on some of the most serious issues. Indeed, the top three most commonly fixed issues were some of the most serious: null pointer dereferences, resource leaks and concurrent data access violations.
As the report notes, these Big Data projects fixed nearly 50% of the resource leaks, a rate consistent with the level Coverity finds in C/C++ projects. But over the 2013 Java resource leaks found by Coverity’s report, only 13% were addressed by 2014.
It Takes A Community
Of course every project—proprietary or open source—tries to squash its bugs. That’s par for the course. But these open source Big Data projects have something going for them that no proprietary code can match:
Community.
It’s easy to point to things like the Shellshock exploit as a failure of open source community. But this misses the point of open source.
Open source isn’t necessarily about crafting better code from the outset, though there is significant motivation to release high-quality code when you know others could be reviewing it. Rather, open source enables discovery of problems and then communal iteration to resolve them.
As Simon Phipps writes, sometimes it’s enough simply for a community to be able to spot the source of a problem after it has happened:
The big difference [between proprietary and open-source software]? We would likely never know they applied [with proprietary software]. Closed development by unknown teams hidden behind corporate PR would seek to hide the truth, as well as prevent anyone from properly analyzing the issue once it became known.
In the case of open-source Big Data projects, entire industries are being reshaped by data, data stored, moved or analyzed by Hadoop, MongoDB (my former employer, BTW), Spark, Cassandra and other open-source projects. Those industries have a huge, vested interest in making sure these projects continue to get better and better.
Which is why it’s time for every company to become an open-source company, helping to build the software upon which every organization increasingly depends.
Lead image courtesy of Shutterstock