

With as many as 67.2 million viewers worldwide, the latest round of U.S. presidential debates were the most closely watched since 1980, when Ronald Reagan delivered a crushing blow to then-President Jimmy Carter.
Yet with that great an audience, in all three appearances, President Barack Obama made one of only two brief mentions of information technology as an American asset. “If we don’t have the best education system in the world, if we don’t continue to put money into research and technology that will allow us to create great businesses here in the United States,” stated the President toward the end of the third debate Monday, “that’s how we lose the competition.”
Former Massachusetts Governor Mitt Romney followed up, literally in the last few minutes, by framing U.S. digital technology in terms of its value to China: “They’re stealing our intellectual property, our patents, our designs, our technology, hacking into our computers, counterfeiting our goods,” Gov. Romney said.
Regardless of one’s feelings of how the candidates performed over the past few weeks, the absence of any substantive discussion of the key success story of American industry — information technology – makes the divide between politics and reality crystal clear. The debates offered more than ample opportunity to frame this country as the champion of free information and the harbinger of the fastest growing industry since petroleum. Big data, the cloud, and information services delivered over the Web are the key to small business growth. But it was as if neither candidate had time enough to glance at the world outside their jet cabin windows.
Virtual Product, Real Industry
The rise of big data as big business points to the urgent need to restructure data centers. This comes in response to three factors that have completely changed in just five years:
- The almost inconsequential cost of data storage, precipitated in no small part by the declining cost of overseas manufacturing labor;
- The explosion in processing power per megawatt, which led to rapid deployment of parallelism that enables analytics functions that were impossible for single-threaded processors;
- The sudden appearance of Web-based languages that enable lightweight apps to perform the same tasks that, just a few years ago, required mainframes and even supercomputers.
It may be difficult to calculate the value of big data contribution to the nation’s gross national product. But the longer we go without including data as an economic product, the more we may be blinding ourselves to an aspect of true American recovery – along with the jobs and brighter futures that come with it – happening right in front of our faces.
Jack Norris, who’s the VP of marketing for San Jose-based MapR — which I introduced you to last December – leads the promotional efforts for one of the commercial vendors of Hadoop, the open source big data technology. As Norris helped verify, a recent Indeed search for full-time Hadoop-specific jobs advertised as earning at least $100,000 per year, yielded 1,377 results. At the top of the list: Hadoop Deployment Manager for Intel. Norris has been generating these searches over the past year, and has noticed an exponential job demand curve, from literally nothing to colossal.
Norris agrees with IBM’s Anjul Bhambri, whom I interviewed last February, about the growing necessity among businesses for a new kind of role called the data scientist. “It’s not the statistician/PhD, necessarily, that will be the data scientist of the future,” remarked Norris in an interview, citing Google’s now-classic principle that simple algorithms in bulk can outperform complex arithmetic. “What we’re seeing is, when you throw data at simple algorithms, you don’t have to have complex models to approximate what the truth is. You take all the data, and you find where the patterns are, the issues – that’s the wave of the future.”
Rethinking The Database Application
Hadoop has come unto its own as an analytics resource, for observing patterns in huge collections of data across multiple volumes, and reducing those patterns to explainable variables and formulas. One tool in Hadoop’s toolkit, called MapReduce, is the origin of MapR’s brand name.
Because big data methodologies, including Hadoop, are transforming the data center, research that years or even months ago could not have seemed feasible, are now not only conceivable but remakably inexpensive. One example Norris cites comes from Ancestry.com, which now offers customers an at-home DNA sampling kit. Through the compilation of an unfathomably massive genetics database, Ancestry.com is uncovering thousands of genetic links between distantly related individuals – links that history alone could never have illuminated.
Consider if the same resources were applied to highly important, federally funded projects that mostly or entirely rely upon database analysis, such as comparative effectiveness research. This is the long-term historical evaluation of medical diagnosis and treatment strategies. Specific aspects of this research qualify for federal grants, including $1.1 billion in funding to the National Patient Advocate Foundation just for the database. Big data technologies could conceivably reduce the costs required to run this database by three orders of magnitude.
Which would be more than enough to save Big Bird.
Unifying The Unifiers
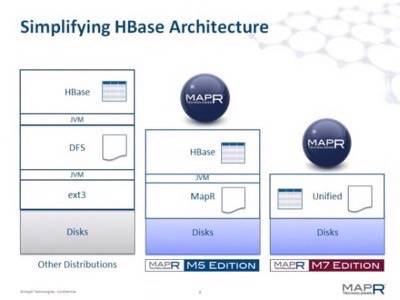
The types of innovations necessary to facilitate such cost reductions are being unveiled literally by the day. Just Tuesday, MapR announced the M7 edition of its database architecture, which reduces the number of engine components yet again. The company’s goal is a unified database structure where “big data” and “data” are essentially the same – where HBase and dBase, if you will, are mere format distinctions.
“The premise, driven by the original Web 2.0, that Hadoop can be its own ecosystem with its HDFS [file system] API to which you rewrite everything, doesn’t really recognize what’s happening in a lot of organizations,” explained MapR’s Norris. “The ability to take Hadoop and open it up through open standards like NFS, ODBC, or REST for management, or Kerberos for security, so it can easily integrate with existing processes and solutions, is a huge step.” He cites the case of one MapR customer, aircraft maker Boeing, which reduced the cost of a database integration project to near-zero. Instead, it used M7 to avoid rewriting a million lines of legacy code in Java (which would have been required for M5), and integrate existing data with M7’s big data store.
“Big data is an approach where you’re doing compute and data together,” he continued, “and you’re not concerned about the data that you’re handling. You don’t have to pre-process it, segment it, decide what type it is and then route it to different clusters or silos. It’s just there. The developer doesn’t have to understand what his limitations are; he can just process the data.”
So if anyone out there is looking for suggestions to fill in those missing details on how the budget cuts Obama and Romney keep arguing about can be implemented… we’ve got our hands up over here.








