The huge problem for online services is that traditional SQL database managers don’t scale up when database sizes approach “exascale” – the tremendous and fast-growing repositories needed by services like Facebook and Twitter. There’s nothing conceptually wrong with SQL, it’s just that the underlying RDBMS architecture does not perform well with these tremendous workloads.

Simpler database constructs can handle bigger workloads, as long as the work they do stays more along the lines of simple storage and retrieval and doesn’t get too analytical. Today, a new vendor named DataStax whose backers include Rackspace is launching a commercial rendition of an exascale database manager that marries an open source database manager project launched at Facebook with an open source distributed processing project started at Google.
Facebook as it stands today would be impossible without its engineers having developed a new database construct for its Inbox Search system. Dubbed Cassandra in 2009, Facebook distributed this system to the open source community, perhaps with the understanding that even if Cassandra holds the keys to Facebook’s kingdom, it’s too late for anyone else to use those keys to knock its castle down.
Cassandra – which lies at the core of the new DataStax Enterprise project – is based on three and only three very simple methods: insert, get, and delete. That’s it; you’ve just learned the entire Cassandra API. Obviously the system omits the “select” construct that typifies SQL; it’s not about finding subsets that match given criteria. But in many Web services, that job isn’t even necessary anyway; the most common function is to retrieve one value from a list, or one node, using only one key as criteria.
While at Facebook, engineers Avinash Lakshman and Prashant Malik had a brilliant revelation: As long as exascale databases didn’t need to be ordinated in rows and tables, perhaps their storage should not be considered on a two-dimensional scale – maybe it’s that two-dimensionality that’s slowing down the process. What if instead the database construct were like a bendy-straw whose head was stretched around and attached to its tail? Each node attached to this base would be like a key attached to a keychain. Who cares where the key is located; a random number generator could make that decision. Such randomization could take care of the whole load-balancing problem; as long as the algorithm is sound, keys are likely to be placed is a fairly well-distributed fashion.
So scaling up is no longer about building a tower on top of an existing foundation. Instead, you simply expand the bendy-straw, making the circle bigger but maintaining the even distribution. The data model can then align these nodes onto any number of simultaneous columns, making the structure essentially multi-dimensional as long as you consider a “dimension” a common attribute. And replication can take place at the per-node level, rather than making sure the entire database gets copied multiple places. This way, the software can be responsible for resolving node failures and doesn’t have to spend its time compensating for hardware failures which, as storage arrays get larger, will be an everyday occurrence. (A complete rundown of Lakshman’s and Malik’s Cassandra construct appears in this PDF.)
Or, as a DataStax white paper (PDF available here) puts it: “What is true about most – if not all – NoSQL databases is that they don’t conform to the standard Codd-Date relational model, where data is normalized to a third logical form. Such data structures often require resource-intensive join operations to satisfy end user requests. Instead, data in a NoSQL database is greatly denormalized and resides in structures organized in a variety of formats (e.g., columnar, document, key/value, graph).”
In April 2010, with Rackspace’s blessing, two of that company’s engineers, Jonathan Ellis and Matt Pfeil, left to form Riptano, with the initial charter of providing commercial support to Cassandra adopters under the Apache license. Last January, in a makeover move to look more like a database vendor than a social network, Riptano became DataStax. Now, it’s this new company’s mission to put a SQL-free exascale database manager on the map, at the same time competitors such as Oracle are boosting their marketing to cement their customer bases.
“Cassandra is a highly scalable and high-performance distributed database management system that can serve as both a real-time database (the ‘system of record’) for online/transactional applications, and as a read-intensive datastore for business intelligence systems,” reads a DataStax white paper (PDF available here). “Cassandra is built with the assumption that failures can and will occur in a database infrastructure. Therefore, data redundancy to protect against hardware failure and other data loss scenarios is built into and managed transparently by Cassandra. Furthermore, this capability can be configured to be quite sophisticated so that data in a single cluster can be distributed across multiple, geographically dispersed data centers, between different physical racks in a data center, and between public cloud providers and on-premise managed data centers.”
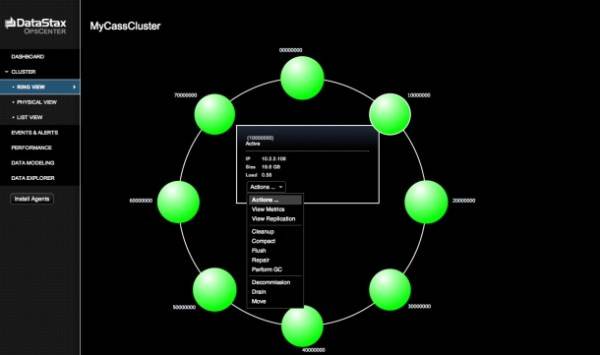
The system is managed using a browser-based tool called OpsCenter, where admins may obtain the status of the system’s ring-shaped clusters, as well as perform Hadoop analytic jobs. With a number of major Cassandra deployments having already taken place, including with well-known names such as WebEx, DataStax’s buildout strategy looks sound and well-supported. The company is also making a Community Edition of the database available to developers and database architects free of charge.