
Until the last few years, large scale data processing was something only big companies could afford to do. As Hadoop has emerged, it has put the power of Google’s MapReduce approach into the hands of mere mortals. The biggest challenge is that it still requires a fair amount of technical knowledge to set up and use. Initiatives like Hive and Pig aim at making Hadoop more accessible to traditional database users, but they’re still pretty daunting.
That’s what makes today’s release of a new free edition of EMC’s Greenplum big data processing system so interesting. It draws on ideas from the MapReduce revolution, but its ancestry is definitely in the traditional enterprise database world. This means it’s designed to be used by analysts and statisticians familiar with high-level approaches to data processing, rather than requiring in-depth programming knowledge. So what does that mean in practice?
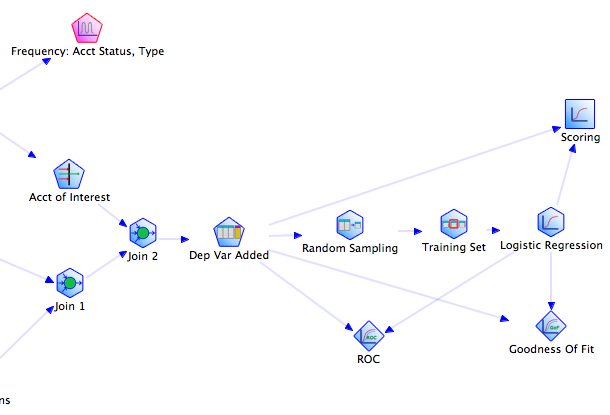
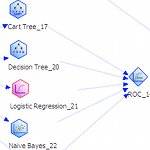
Visual programming can be a very effective way of working with data flow pipelines, as Apple’s Quartz Composer demonstrates in the imaging world. EMC has an environment called Alpine Miner that lets you build up your processing as a graph of operations connected by data pipes. This offers statisticians a playground to rapidly experiment and prototype new approaches. Thanks to the underlying database technology they can then run the results on massive data sets. This approach will never replace scripting for hardcore programmers, but the discoverability and intuitive layout of the processing pipeline will make it popular amongst a wider audience.
Complementing Alpine Miner is the MADlib open-source framework. Describing itself as emerging from “discussions between database engine developers, data scientists, IT architects and academics who were interested in new approaches to scalable, sophisticated in-database analytics,” it’s essentially a library of SQL code to perform common statistical and machine-learning tasks.
The beauty of combining this with Alpine Miner is that it turns techniques like Bayes classification, k-means clustering and multilinear regression into tools you can drag and drop to build your processing pipeline.
Traditionally it’s been a development-intensive job to implement those algorithms on large data sets, but now they’re within the reach of analysts without requiring engineering resources. Even better, because it’s open-source users of other database systems are able to take advantage of the code, though then they won’t benefit from Greenplum’s underlying processing engine.
This release from EMC is only free for non-production use, and the majority of the product is not open-source, so it’s definitely not an immediate threat to Hadoop adoption. It is a sign that the traditional enterprise world is starting to pay attention to the wider world though, and demonstrates some of the areas where free solutions are lacking, especially in terms of their ease-of-use.
The engine is an extremely powerful tool for large-scale machine learning, as this example from O’Reilly’s Roger Magoulas demonstrates. Will it open up these sorts of enterprise tools to a whole new set of academic and startup users?








