











So you have that old screenplay from 10 years back that you printed out but long ago lost the floppy disc you’d it saved on. If it’s time to resurrect it and you don’t feel like taking a couple of days to tediously type the whole thing up again, then no fear, Google is here.

Google is taking another one of its experimental features and taking it mainstream: optical character recognition.
The feature originally started out at Google software engineer Jaron Schaeffer’s 20% project before finally being added as an experimental and now full-fledged feature of Google’s cloud-based answer to software like Microsoft Office, Google Docs.
Optical character recognition is the automatic translation of text, whether handwritten, typed or otherwise, into “machine-encoded text” – e.g. an editable .txt or .doc file. According to the original release of the feature, OCR “will only work well on high-resolution images, so if the original document is faded and grainy, set the DPI high when scanning it for better results.
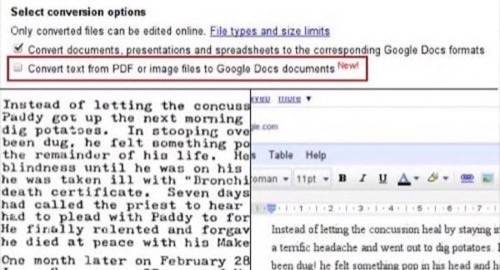
The option to translate an image into text is available on the upload screen and can be used on PDF, JPEG, GIF and PNG files. As warned in today’s release, not all formatting may be preserved, so an original of the scan is included in the document. Currently Google Docs OCR supports English, French, Italian, German and Spanish, but as always, our favorite polyglot Google says more languages are soon on the way.
The only problem so far might be that it just doesn’t work all that well. The official Google announcement only mentions documents, so we found some handwritten images on the Web, tried uploading them and got zip, zilch, zero for text. As Chris Cameron wrote the other day, when the feature was first noticed on the unofficial Google Operating System blog, “those who rely on OCR heavily will likely be disappointed with the features and may have better results with commercial solutions.”




















