











Google just announced that it has acquired reCAPTCHA, one of the leading providers of CPATCHAs, the hard-to-read puzzles you often have to solve before you can sign up for a new web service. Google, of course, isn’t so much interested in owning software that can generate CAPTCHAs – that’s an easy problem to solve – but is looking at reCAPTCHA as a way to improve the optical character recognition (OCR) software it uses for large scale text scanning projects like Google Books and the Google News Archive Search.

According to Google, reCAPTCHA is currently in use on over 100,000 websites to prevent spam and fraud. the reCAPTCHA team, which is currently based at Carnegie Mellon University, will join Google.
Solving CAPTCHAs to Transcribe Books
We took detailed looks at reCAPTCHA and how it works last September and in early 2007. In short, reCAPTCHA has found a nifty way to crowdsource book transcriptions. When users solve a CAPTCHA through reCAPTCHA, the software will give users two words: one with a known answer (the control word) and one where the OCR software wasn’t quite sure what the word was. Once a certain number of users have solved the suspicious word with the same result, it becomes a control word itself and the OCR software can learn this word.
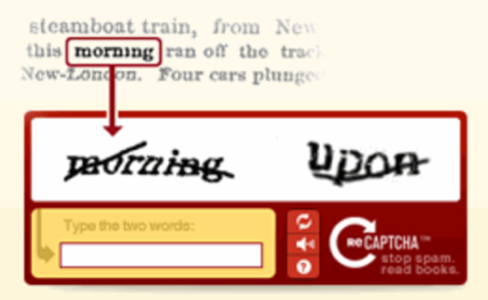
Now, Google will be able to use this same technology to improve its own OCR efforts. Google currently makes over 1 million out-of-copyright books available for download through Google Books and one of the main arguments against these books has been the fact that these texts are not edited and include a lot of OCR errors. With reCAPTCHA, Google could potentially bring the error rate down dramatically and make Google Books even more useful.




















