
It’s been more than ten years since Tim Berners-Lee first spoke about the semantic web and computers indexing all web-based data. He said, “The day-to-day mechanisms of trade, bureaucracy and our daily lives will be handled by machines talking to machines. The ‘intelligent agents’ people have touted for ages will finally materialize.” Since then a handful of companies have attempted to tackle the issue of machine-based indexing and language interpretation. None of them are perfect. Below are 6 unique approaches to semantic data collection.

1. Powerset
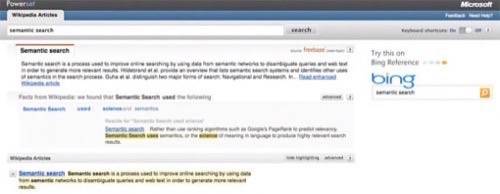
This site was one of the first to publicly apply machine-based natural language processing to a consumer search engine. Nevertheless, because public expectations were so high, when Powerset launched a Wikipedia-only beta,
The site was acquired by Microsoft shortly after the initial launch and the team has been low key ever since. While Powerset is one of the definitive semantic engines in existence, Microsoft is currently concentrating on using Powerset’s technology to index Wikipedia pages in Bing. Powerset’s search result pages actually contain a “Try this on Bing Reference” note in the sidebar of the site.
2. Cuil
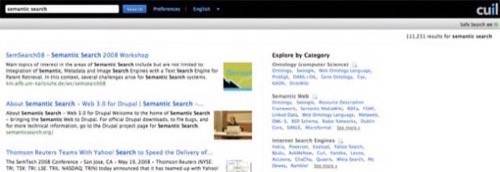
This team touted its language processing product as being much faster to index pages than Google; however, consumers rarely covet speed over quality and the site
was criticized right from the start
. Expectations were not met as Cuil’s claim to 120 billion pages indexed did not match up to the results on
Google’s reported 1 trillion unique URLs.
However, what Cuil did right was separate related search results from regular web results. That being said, without any human intervention, the related results are often bizarre and irrelevant. For instance, my name produces the rankings of Ultimate Fighting Challenge Champions.
3. Hakia

This is a natural language search engine where sponsored results, regular web results and “credible” web results are broken down visually into separate categories. Similar to Wikipedia, Hakia
employs a community monitoring system for credibility
and “credible” results must be peer reviewed and seemingly free of corporate interest. One of the great features of Hakia is that users can tab over the site to show only images or news.
4. Worio
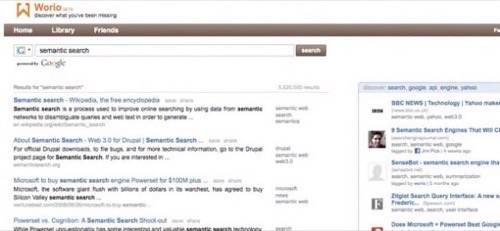
Worio is considered a “discovery engine” as it is not technically a search engine destination site. While users are still required to visit the
, search is actually powered by Yahoo, Google or Windows Live search. Regular web results appear in the larger left-side column and natural language-based “discoveries” appear on the right. These discoveries are further refined by personal bookmarks and shared relevancy with Facebook friends.
5. Ubiquity
Ubiquity for Firefox from Aza Raskin on Vimeo.
Ubiquity is perhaps the opposite of a semantic web engine, but it serves a similar function for those looking to aggregate useful data. The Firefox plugin allows users to create command lines that incorporate natural language search with a series of mashups. Users can then combine relevant data from Craigslist, translation tools, maps, reviews and social networks for easy user visualization. While the end product is an extremely useful document, users may not be ready for the drastic behavioral change of using command lines for semantic data collection.
6. Semanti
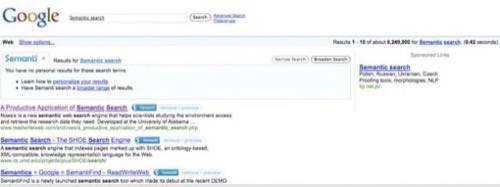
From a consumer standpoint, Semanti sits somewhere on the spectrum between Worio and Ubiquity. ReadWriteWeb
reviewed the product earlier this week
and like Ubiquity it is a Firefox plug-in rather than a destination site. However, like Worio, it employs leading search engines, bookmarking and Facebook friends to produce results. Semanti’s key difference is that it prompts users to choose from multiple definitions prior to completing the search. Decision-making is actually human-powered rather than machine-powered. CEO, Bruce Johnson, said, “I tried machine-based semantic tagging, but my priority has always been a faster search experience.” While this is not the “use of intelligent agents” that Berners-Lee suggested, it is a “semantic” tool in that it helps the user distill meaning and relevancy from language.
If you’ve got more examples of semantic data collection tools, list them in the comments below.









