
Nova Spivack’s semantic web company Twine is developing a free service to write and host semantic ontologies; the classification trees that enable machines to put concepts in topical context. Ready to play Aristotle and create an ontology of cheese, model airplanes, global anti-hunger organizations or any other topic?

What blogging was to publishing, a simple tool that made far more people able to participate, Twine’s new ontology writing and hosting service could be to the act of teaching machines about new topics.
The company wouldn’t let us publish the new service’s name but says it is aiming for a launch date this year, as soon as a go-to-market strategy and appropriate partnerships are lined up. The ontologies created won’t only work on Twine; they will be referenceable by semantic apps anywhere around the web.

Twine Could Surpass Delicious in a Matter of Months
Twine’s public product lets people bookmark items like web pages and videos into topical collections. The service then analyzes the contents of all the bookmarks to identify the key concepts, people, places and other information automatically. It’s like tagging in Delicious but automated and, in theory, more thorough than any human being would be in assigning tags.
Compete.com says Delicious gets about 2 million unique visitors a month and has stopped growing. Twine just passed 1 million uniques and is growing fast. Spivack said that 40% of that traffic comes from Google, and sure enough those Twine pages look awfully juicy from a spider’s perspective. Spivack expects Twine to hit 2 million uniques in a matter of months and that looks like a credible claim to us.
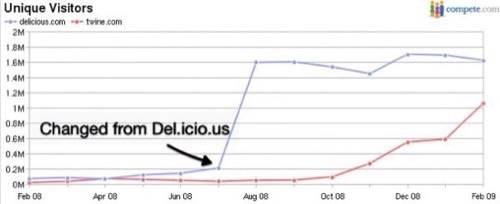
The number of saved items is far greater in Delicious than in Twine – about 150 million vs. 3 million. Spivack says though that the company will soon turn back on its system that crawls all the links on bookmarked pages. Those linked-to pages will be automatically bookmarked and analyzed too, quickly expanding Twine’s total archives.
So by this summer, Twine could be bigger and more visited than Delicious. We wrote a scathing review of the Twine user experience when the long-awaited service began to launch last year. The site has changed a lot since then and we’re excited about the company’s plans for the future. We are still concerned about the company’s ability to make its interfaces really usable — but if they can, then look out, internet.
Twine and the Semantic Web
The semantic web is a paradigm that adds standardized, structured markup to web content so that savvy applications can comprehend the key topics of any web page. Publishers can do that when they publish, or services like Twine can create the semantic markup from the outside. The automatic tagging Twine does is actually semantic markup.
For example, you can’t ask Google today to show you all the book reviews around the web that were written by friends of yours who live in New York – but semantic search engines could make such a query trivial and use that information as the ground level for building more sophisticated features on top. It’s a form of standardized metadata. It turns free text into data that can be mashed up.
Semantics Plus Ontology Equals Meaning
Spivack says that his existing product, Twine, is just one of a number of applications that only extract key concepts (people, places, key terms) out of a web page. Placing those concepts in context is the next step.
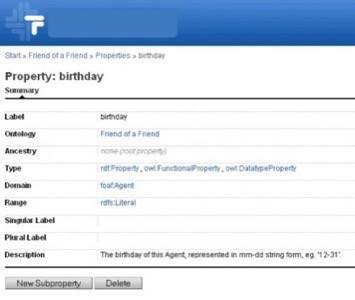
Twine can tell you that a web page is about goat cheese, for example, but it doesn’t yet know how to infer that the page is also about a dairy product – the larger category that is not explicitly stated in the article. An ontology is that context, be it a dairy ontology, a cheese ontology or a new node in the existing accepted ontology of food.
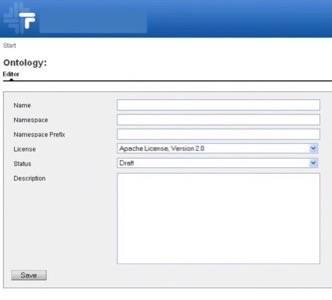
Those new ontologies can be created using Spivack’s simple, open source authoring tool and then hosted on his open source community site for ontologies. It’s open source authoring like WordPress and code hosting and discussion like Sourceforge.
Either Twine or a third party will then combine the extracted “entities” (people, places, key terms) with an appropriate ontology and that company’s “inference engine” to build a full picture of what a web page is about and where it stands in relation to everything else.
Busting Out of the Tech Ghetto
The limited number of ontologies that have been authored to date are largely centered on technology topics. An easy ontology authoring tool could change that radically. A standardized, accessible ontology can shine a light on a whole new part of the world. Once that topic has been illuminated for the eyes of a semantics reading machine, web developers can build services that intelligently make use of the new information.
Spivack says that heavy-duty ontologies that require computationally intensive logic navigation will still need to be built using heavy-duty desktop apps. But web applications that just need data served up smartly will work well with the kinds of ontologies that can be written with Spivack’s new authoring tool.
Ready for the whole, diverse internet to be contextually understandable by web applications? Ready to contribute to the creation of those contextual explanations yourself? Keep your eye on Nova Spivack because that’s what he’s aiming to make happen.









