
Freebase, the first product of semantic web company Metaweb, is an open, semantically marked up database of information that we called one of the “10 semantic apps to watch” last year. With $57.4 million in funding, a smart team, and a tech legend in Danny Hillis at the helm, Metaweb is considered to be one of the most serious players in the Semantic Web space. Yet the company’s
efforts to date have been met with skepticism. Particularly, people have asked how is Freebase different to Wikipedia? Jamie Taylor, the Minister of Information at Metaweb, spoke at the SemTech 2008 Conference that took place in San Jose last week in an effort to dispel some of that skepticism.

What is Freebase?
Jamie has an interesting title: Minister of Information, and his primary responsibility is to seed Freebase with information and ensure the quality of the data. According to Jamie, Freebase is “open shared database of the world’s knowledge.”
This sounds the same as Wikipedia, but it is really quite different, because at the heart of Freebase are the ideas of semantics and openness via API.
Unlike Wikipedia, which is a free form database, Freebase is structured, where concepts and relationships
are interlinked into a gigantic network or graph. Another important difference is that Freebase is all about its API.
Any information contained inside the database is accessible and can be retrieved via queries. In addition, the data
in Freebase is under a Creative Commons license – meaning that is readily exportable and useful by others.
When it comes to defining the meanings of things, Freebase is focused on community, with collective editing, attribution,
and collaboratively built semantics. This last point is quite crucial – the founders of Freebase believe that meaning
has to emerge from the collaboration between users. As such, Freebase is one of the first experiments of web-scale
social contracts. The site is really focused on the notion that information is not encumbered by licenses and is free to use.
What is in Freebase Today?
Data comes into Freebase from many sources: Wikipedia, Flickr, the US Department of Commerce, Music Brainz, the USGS,
SFMOMA, the US Exchange Commission, Chef Moz, and many other places. Right now the information is mostly about people and places, but the system
is engineered to have a wide range of data types. As an example of “People” information, there
is a lot of information in Freebase about artists along with their artwork and place in history.
More esoteric types of information you might find in the database include airplanes, french cheese, tropical storms in the 90s,
oil companies, and candies.

Freebase also contains lots of other kinds of data and has:
- 3.4 Million Subjects
- 750K People
- 450K Locations
- 50K Companies
- 40K Movies
- … Over 1K Data Types with over 3K Properties
Data Representation in Freebase
While Freebase certainly has long way to go before it can claim completeness of information,
its core idea of object representation and linking seems very solid. Each object in Freebase is unique.
As more information comes into the system about an object, more links are created about it in the system.
It is particularly interesting how Freebase establishes object identity and decides that two concepts (or subjects) are the same.
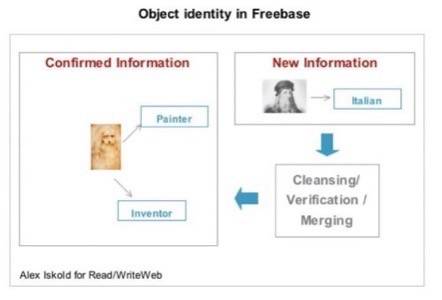
The diagram above illustrates the idea. When a new source of information is added to Freebase, it is parsed into
entities and facts. The new information is then cleaned up and is merged with the existing system. But
the merge only occurs if the system determines that the two bits of information are really about the same subject (in
this case Leonardo Da Vinci). This is a powerful approach which allows Freebase to grow the knowledge around individual
subjects. What is also interesting is that Freebase allows human editing to reconcile situations when the system
is unable to automatically link the two concepts together.
Each permanent object in the system has a GUID – a unique identifier, something like this: #9202a8c040000064…..
The identifier can be used to refer to the object via URL and via queries. In addition to the GUID, there are other
ways to refer to the object, for example, http://www.freebase.com/view/en/leonardo_da_vinci. Beyond that, there are even other
aliases, for example, you can refer to a public company by its stock ticker symbol. But regardless of the reference, the key point is that
you end up with the same, unique node in the system.
Freebase also has the ability to create new domains and types that describe new concepts, for example, science fiction movies.
There is a way to attach new data types to the existing domains, and then these types can be shared and used by other users.
The idea is that you can model things with the fine grained resolution that you need and then you can invite people
to help you refine and evolve your models. An example is the motorcycle community, which evolved out of an effort led by
one guy and who was then joined by others, and has since been promoted to the top level. The community process
is about merging private types to build common models.
What Can You Do With Freebase?
Freebase is not a formal system, it is not a reasoning engine, it is just a knowledge repository, a database.
To query Freebase you use the Metaweb Query Language (MQL), which is based on JSON. The language is meant to be very simple
and it is actually very interesting as well. The idea is that you fill out a tree which represents a partial
graph with pieces that you know and then the system basically fills in all the slots that you left blank
and delivers back all possible subgraphs.
For example, say you are watching a movie and you can’t tell what it is.
You know that the movie stars Patrick Swayze and an actress who was also in “Tank Girl.” So you create a movie query and express all these facts, using JSON-style syntax.
And when you run the query you get back that the actress is Lory Petty and the movie
is “Point Break” and you also get links to IMDB. So the query and the results have the
same structure and to find matches you simply traverse the set of results that is returned.
Building on this example, Freebase is really meant for complex inferencing queries, the sorts
of questions that Google has no way of answering using its statistical frequency algorithms.
For example, what US senators took money from a foreign entity? Turns out that both Barak
Obama and Hillary Clinton received donations from UBS AG, based in Switzerland. That is a complex
inferencing query that needs to be expressed in a query language before it can be answered
and so questions of this nature are outside of the reach of any search engine — and Wikipedia too, for that matter.
Resources
There is quite a lot of activity going on around Freebase today.
Many enthusiasts are building small proof of concept applications showcasing what can be done
in the future with this powerful database. You can stay on top of the cutting edge stuff coming both from the Freebase team and community at: http://download.freebase.com and
http://research.freebase.com









