
As Richard MacManus recently predicted, in 2008 we’ll witness the rise of semantic web services. From the native support for Microformats in Firefox 3,
to the New York Times’ utilization of rich headers metadata, to this week’s release of the Social Graph API by Google,
semantics are starting to slip onto the web. The impact is being felt because large companies are really starting to focus on structured information.

In the same vein, last week Reuters – an international business and financial news giant – launched an API called Open Calais.
The API does a semantic markup on unstructured HTML documents – recognizing people, places, companies, and events. This technology is
the next generation of the Clear Forest offering, which Reuters acquired
last year. We have profiled Clear Forest on ReadWriteWeb and in this post we will look at what Reuters opened up and why.
Open Calais API Basics
The idea behind Calais is simple – identify interesting bits into metadata in documents.
In this implementation the focus is on People, Companies, Places, and Events, but surely the technology
can be adopted to other entities. The heavy lifting is done by the combination of a natural language processing
engine and a massive hard coded, learning database that Clear Forest has built.
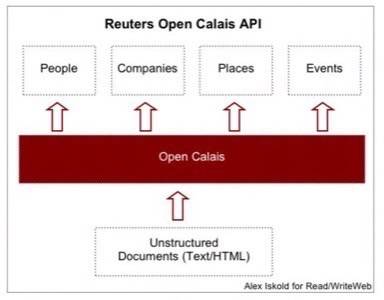
For any document submitted into Calais, entities are identified, extracted and annotated.
For example, when the press release
about the acquisition of Clear Forest is analyzed, the following meta data is identified:
- Relations: Acquisition, CompanyInvestment, PersonProfessionalPast
- Organization: Palo Alto Research Center
- IndustryTerm: broader search development effort, text search, text analytics software, …
- Company: Time Warner Inc.,Reuters, Pitango Venture Capital, Inxight, ClearForest Ltd, …
- Person: Gerry Campbell
- Country: United States, Israel
- City: Tel Aviv, SAN FRANCISCO, Waltham
This is rather impressive set of information. According to the documentation page, the response is delivered in under one second for
larger documents, and much faster for smaller ones – in other words, real time or near to it.
What was not quite clear from the documentation is if Calais can deal with raw HTML pages. It appears
that the API requires an XML document, where the main text is marked differently from the header and footer.
Ideally, an API like this should be able to accept URLs, because distilling structure from HTML would not be
trivial for developers. Another thing that we noticed is that the resulting document is extensively marked up.
What the developers get back is literally the output of the Calais engine. It would be good to be able to get
a lighter version, which simply identifies entities and their positions in the text.
Currently the API is free for both commercial and non-commercial use and Reuters says it is prepared to
scale for a massive concurrent demand. The question is then how can this be used?
What is Calais Good For?
There are quite a few interesting applications for this technology. First – better search.
Knowing the kinds of entities in the text allows developers to build intelligent search engines that look for related content.
For example, imagine a page on Reuters with this press release and in the sidebar links to learn more
about Clear Forest, Reuters, Inxight, etc. Similarly, Calais could enable links to countries and cities mentioned in the document. And these searches need not be generic searches, but rather specific vertical ones.
Another application would be to build engines like Inform,
which automatically inserts links into raw text. By automatically identifying entities in the document, Calais also identifies
what should be linked. So a big piece of Inform’s secret sauce is trivialized. The rest is basically a raw search through
the archive, which can be done with a Google custom search engine, for example. It is possible that more tech savvy media companies
could leverage Calais in exactly this way.
Another application is structured alerts. Modern alert systems are keyword based and suffer from false positives.
Using Calais it is possible to build precise alerts for people, companies, places and events like corporate acquisitions.
With the flood of junk in our RSS readers this is rather welcomed news.
Yet another application would be to incorporate on the fly text analysis into the browsers.
In a way, this is not much different from having Microformat annotations on the page, except that the annotations are delivered on the fly. For example, a browser could call Calais on document load and
obtain a list of people, places, companies, etc. which are embedded in the document. With this information
the browser would be able to create a more interesting, more contextual, and relevant experience.
What’s In It For Reuters?
Reuters has opened up a generous API, but why?
During our interview, Gerry Campbell, the
President/Global Head of Search & Content Technologies at Reuters, explained that Reuters wants the world to be tagged.
When the world’s content is quickly and readily accessible to their customers, Reuters wins. Semantic technologies result in
better, faster, more precise and relevant information, and Reuters, as a big player in the information
space, wants to be one of the first companies delivering this kind of experience.
Beyond an outstanding customer experience, Calais leads to a unique, attractive set of assets.
First – a growing semantic database of people, places, companies and events. With each new document submitted
into Calais the database gets richer and more complete. This is a roadmap to a semantic business powerhouse,
which is clearly a great position to be in for any business media company. And in a way, what grows beneath Calais
will not be that unlike Freebase. Except of course, it is happening completely automatically.
The second big advantage of having an open API is training the system. Any AI-based solution like Clear Forest
is in constant need of tuning and evolution. Having other companies use the system would allow the engineers
to run into cases that they have not thought about and broaden the capabilities of the system. Campbell told us that Calais is already processing a significant subset of Reuters information in nearly
real time. This is both impressive technically and smart from an engineering point of view – it is an “eat your own dog food”
approach to building a great piece of software.
Conclusion
The Calais API is another big win for top-down semantic web technologies.
Using a mix of natural language processing, AI techniques, and a massive databases, Reuters’ solution extracts important bits of information from
raw HTML pages. People, Companies, Places, and Events are really at the heart of many business articles, so being able to
instantly identify them in the text is a big deal. From better search to better cross-linking and more intelligent browsing, the Calais
API is an invitation to tap into one of the most powerful and pragmatic semantic platforms that exists and works today.
What sort of things do you envision to be possible with Calais? What applications would you like to see built with this platform?









