











Have you ever wondered what the English language looks? Yeah, neither have I. But a group of researchers at the Massachusetts Institute of Technology and New York University did, and tapping into the billions of images freely available on the Internet, they came up with a visual map of the English language using nearly 80 million of those images. The images are arranged based on the semantic relationship between words, and thus, according to the researchers, the project explores “the relationship between visual and semantic similarity.”
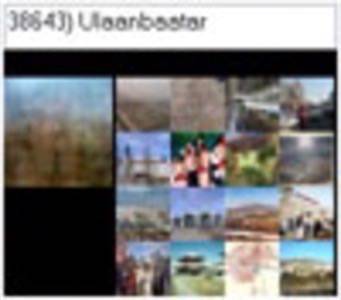
The researchers started by locating images for all 75,062 non-abstract nouns in the English language (though, to be honest, some of them seem pretty abstract — Ulaanbaatar, for example?). For each noun, the researchers found multiple images, they then combined the images into an average (sort of a blob of colors) that represents that word visually. They used 79,302,017 images in total.

“The list of nouns was obtained from Wordnet, a database compiled by lexicographers which records the semantic relationship between words,” explains the project’s web site. “Using this database, we extract a tree-structured semantic hierarchy which we use to arrange tiles within the poster. We tessellate the poster using the hierarchy so that the proximity of two tiles is given by their semantic distance.”
The result is a stunning visual map of the English language. As Angela Gunn points out, it is thus rather ironic that the very first word on the grid is “blind.”
Oh, for anyone who was wondering, Ulaanbaatar is the capital of Mongolia…




















