
Brad Fitzpatrick recently
wrote an elegant and important post about the Social Graph, a term used by Facebook to describe their social network.
In his post, Fitzpatrick defines “social graph” as “the global mapping of everybody and how they’re related”. He went on to outline the problems with it, as well as a broad set of goals going forward.

One problem is that currently you need to have different logins for different social networks. Another issue is portability
and ownership of an individual’s information, explicitly and implicitly revealed while using social networks.
As was recently asserted in the Social Bill Of Rights
and as has been advocated for a while by Attention Trust Principles, users
want to own their personal information – including their chunk of the Social Graph.
The problems are all interconnected – what makes up a Social Graph, how it is treated by social networks, what the
APIs and standards are, as well as who owns the information. In his post Brad
discussed a vision of an open, public asset – controlled by the people and used (and complied with) by
the social networks. Can this vision be realized? While this is certainly
a complex problem, if there is any time when this vision can become reality – the time is now.
In this post we will take a broad look at the definitions and issues with the Social Graph; and explore some ways
in which the standards and laws can actualize.
Quick Primer on Graphs And Networks
In Mathematics, a Graph is an abstraction for modeling relationships between things.
It is no different from a Network, which is a more common term for describing the same thing. Graphs consists of nodes and edges,
or things and the ways that things relate to each other. As it turns out, Graphs are very powerful modeling tools for modeling
natural and man-made systems. Diverse things like the Web, power grids, economies and even cells can be represented
and analyzed as networks.
Note: Images above are from the Visual Complexity Gallery
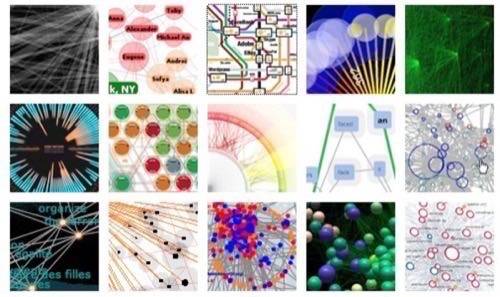
What is also remarkable is that a lot can be said about a graph by looking at its structure; and the evolution
of the structure. For example, epidemiologists use graph structures to predict the spread of an epidemic.
The very same model can be used to understand how wild fire spreads, as well as how to engineer a viral marketing
campaign. The better we understand the structure of a system’s graph, the more we can control it, predict it
and analyze it. An excellent resource for learning about Networks is the the Research Center at University Of Notre Dame.
Quick Primer on the Sociological Graphs
Our society spawns one gigantic social graph. In this graph, each one of us is a node. There is an explicit connection,
if we know each other. For example, two people can be connected because they work together or because they went to school together
or because they are married.
Facebook
Sociologists have been studying these graphs for decades. Famously, the social networks
have a so called Small World property – more widely known as the Six Degrees of Separation.
This is both an anecdotal and scientific observation that we all are connected to each other – no more than six people away. The secret?
It’s because this is how human networks form – dense clusters are inter connected by shortcuts.
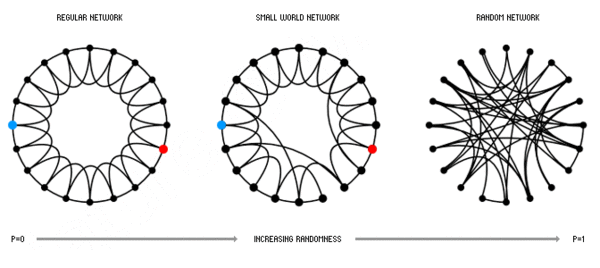
A simple way to think about it is this: your friends know each other, and with time, they meet each other.
If at least one person in a group meets someone from a remote part of the world, the whole group is now
connected to another part of the world. You can learn more about the fascinating science of Smart World Networks
from a book by Columbia Professor Duncan Watts – Six Degrees, The Science of Connected Age.
Key Elements In Digital Social Graphs
With the recent rise and proliferation of social networks, the social graph comes into the spotlight.
Unlike the one that scientists have been studying, this one is digital and defined explicitly by connections
in all social networks. Let’s revisit the main issues that Brad and others have been talking about:
1. People Identity Each one of us participates in multiple networks, but we want to be identified
as the same person in all of them. Brad describes this as a multiple login nightmare. He calls for having
a way to map IDs onto each other, via Node Equivalence:
“Given a single node, say “brad on LiveJournal”, return all equivalent nodes: “brad” on LiveJournal, “bradfitz” on Vox, and 4caa1d6f6203d21705a00a7aca86203e82a9cf7a (my FOAF mbox_sha1sum).”
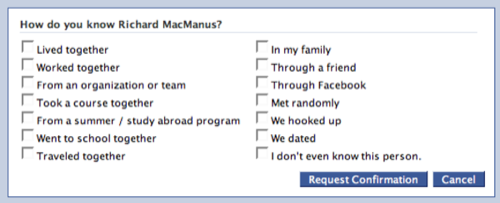
2. Type of Relationships The links between people in social networks are of different types.
Crudely, different types of relationships are a friend, a co-worker, a family member.
There are more fine grained relationships defined in Facebook (see picture above) and Spock, which uses tags
to identify how people are related.
3. Relationships Identity Similar to having node equivalence, there is an issue of edge
equivalence. Although, this issue is more complicated. If two people are connected in one social network, should
they automatically be connected in all of them? Consider an example of a LinkedIn and Shelfari. Just because two
people work together does not mean that they share the same book interests. However, the crux of the issue is not that –
it is actually discoverability. As Brad pointed out, there needs to be a way for a new user who joins a network
to be able to find friends who are already using that network.
Privacy and Ownership of Information
Privacy and ownership of information are at the core of the social graph issues.
Much like there is a conflict of interest
around attention information between online retailers and users, there is a mismatch between what individuals and
companies want from social networks. When any social network starts, it is hungry to leverage other networks.
As it grows, the incentive to share information like social graph and attention with others deminishes
(unless it is done via an API that continues to benefit the network). But as individuals, we do not care about either
young or old networks. We care about ease of use and privacy.

In the ideal scenario, we would like to spend the least amount of time logging in, configuring,
telling the system what we like. We want to use the network to connect and to communicate. More importantly, we want
to not just feel that we are in control, we want to be in control of our personal information. Just like
we choose who to make friends with, we want to decide how our friendship information is used. We think of a social
network as a service that has our eyeballs and can advertise to us, in exchange for connecting us to people we want
to connect to. And as with any service, we want to control our information.
Just wanting to own and control information is not enough though. Companies do not really care, as they
just do what’s in the best interest of their business. So to make companies cooperate, people
need to come together and take a stand. As we have written here
many times before, the best way to take a stand is to form an organization. Organizations have a much better track record of dealing
with corporations than single individuals. The organization can put forth a set of rules and standards
and then work with companies to implement them. This is essentially what Brad is proposing,
and this brings us to the technical aspect of social graph – the API.
The Social Graph API
In his post, Brad explicitly described a need for an API or a service that would broker
the information between social networks. He envisions an open source base database which
accepts information from multiple social networks, then provides it to end-users
via UI or API – as well as allows users to authorize other social networks to find the information.
Architecture-wise, this infrastructure is the same as the one we discussed in our
Attention Economy and
Attention Silos
posts; where we described a read/write database for storing people’s attention.
Indeed, the problem of attention and the social graph are related, since the social graph can be thought of
an aspect of attention.
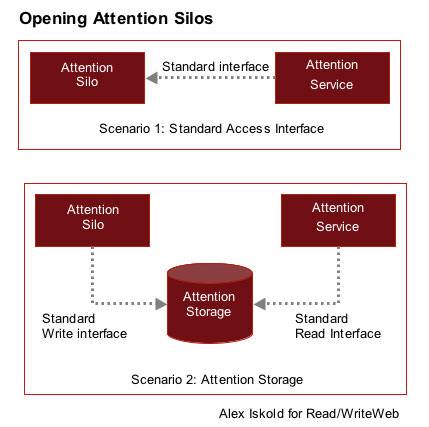
The first technical challenge with this approach is to build a system that can scale.
The second important problem is building a system which is secure. Assuming that both challenges
can be met, the next major issue is getting companies to use this API. Why would Facebook export their
information into this new database? Clearly, it would not. What Brad suggests is that Facebook
and other networks implement an export facility that would allow the users themselves to do it.
This is also not optimal, since people would have to export their information manually.
A more automated approach would be to define an API that all social networks must implement,
so that other networks can query their subset of the social graph. With this approach, when a user joins
a new network, that network can connect to other ones and get the information about its users. It is basically
similar to the Import Your Friends From Email feature common to many social networks these days.
The challenge, again, is to convince the social networks to support this functionality.
Yet, one can not help but think that a similar challenge was successfully solved by another tech community:
Java. The Java Community Process is an industry-wide effort to
come to around a table, to define and drive the implementation and adoption of Java APIs. For example, a big success story
was J2EE standards, where companies like IBM, BEA and Oracle made their application servers compliant with a common
API, making it easier for the applications to be portable. (To be fair, we have to admit that they also stuck
proprietary stuff on top of the standards – but the point is that a lot of things were standardized)
Conclusion
Brad has started a fascinating discussion. What is the Social Graph? Who owns it? What is the API? All of these
questions are likely to shape the evolution of the next generation of the Social Web.
On the surface the issues
are clear and simple, but what is also clear is that it will take a lot of work to get a working solution.
The challenges are conceptual, technical, political, business and educational. A lot of minds need to converge
for the Social Graph, as described by Brad, to happen. Traditionally the tech industry has been able to
come though on critical standards that benefit people. Let’s hope that this will be the case here as well.
Note: top image is from StudiAnalyse Project









