This guest post from David Thompson, principal DevOps engineer at MuleSoft.
Nothing lasts forever. This is certainly true for infrastructure, and it’s most poignantly obvious in the public cloud, where instances churn constantly. Your single-node MySQL service? Not long for this world, man. That god-like admin server where all your cron jobs and ‘special tools’ (hacks) live? It’s doomed, buddy, and it will take your whole application stack with it if you’re not careful.
One question that came up recently within the DevOps team here was: “Given the AWS EC2 service level agreement (SLA) of 99.95, how do we maintain an uptime of 99.99 for our customer applications?” It’s an interesting point, so let’s explore a few of the principles that we’ve learned from building a platform as a service to maintain higher availability than our IaaS provider.
Consider a simple-but-typical case, where you have three service components, each one having a 100% dependency on the next, so that it can’t run without it. It might look something like this:
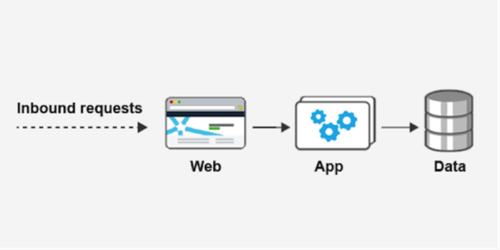
You can calculate the expected availability of this system pretty easily, by taking the product of their individual availabilities. For instance, if each component is individually expected to hit three nines, then the expectation for the system is (.999 * .999 * .999) = .997, failing to meet a three-nine SLA.
Redundancy and Clustering: Never Run One Of Anything
In order to break into the high-availability space, it’s critical to run production services in a redundant configuration; generally, you should aim for at least n+1 redundancy, where n is the number of nodes needed to handle peak load for the service. This is a simplistic heuristic, though, and in reality your ‘+1’ should be based on factors like the size of your cluster, load and usage patterns, and the time it takes to spin up new instances. Not allowing enough slack can lead to a cascade failure, where the load spike from one failure causes another, and so on until the service is completely inoperable.
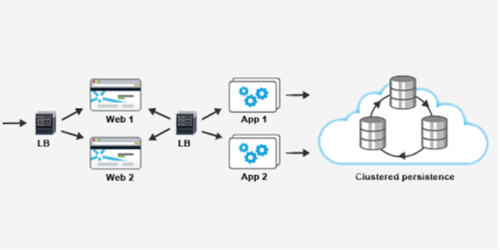
We typically run all of our edge (i.e., externally facing) services as stateless Web apps behind Elastic Load Balancers. This allows a lot of flexibility with regards to replacement of instances, deployment of hot fixes, and the other kinds of maintenance tasks that can get you into serious trouble when you’re running a SaaS solution. The edge services are backed by a combination of persistence solutions, including Amazon RDS and MongoDB, each of which provides its own redundancy, replication and failover strategy. Instances for both API and persistence services are distributed across multiple EC2 Availability Zones (AZ), to help prevent a single AZ failure from taking out an entire service.
Loose Coupling And Service-Oriented Architecture
If you decouple the services so that each one is able to function without the others, your expected availability improves, but it also becomes a lot more complicated to calculate because you need to consider what a partial failure means in terms of your SLA. An architecture like this will probably look a little messier:
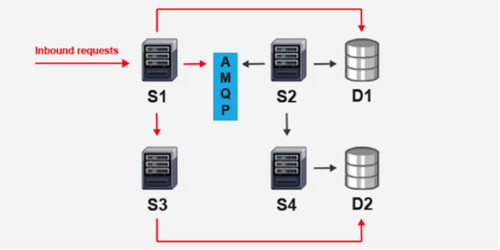
The diagram above shows a typical case where you have several different services, all running autonomously but consuming each other’s APIs. Each of these blocks represent a load balanced cluster of nodes, with the request blocking calls in red and the asynchronous processing in black.
One example of a service-oriented architecture (SOA) that might be structured like this is an eCommerce system, where the synchronous request consumes billing and inventory services, and the asynchronous processing is handling fulfillment and notifications. By adding the queue in the middle, you can decouple the critical calls for the purchase process; this means that S2 and S4 can have an interruption, and the customer experiences no degradation of service.
Since we’re running a platform as a service (PaaS), we have different SLA requirements for customer apps versus our platform API services. Where possible, we run customer apps semi-autonomously, maintaining a loose dependency between them and the platform services so that if there is a platform service outage, it doesn’t impact the more stringent SLA for customer applications.
TDI: Test Driven Infrastructure
Monitoring is really just testing for infrastructure, and like with application code, thinking about testing from the beginning pays huge dividends in systems architecture. There are typically three major categories of monitoring required for each service architecture: infrastructure, application stack and availability. Each one serves its own purpose, and together they provide good visibility into the current and historical behavior of the services and their components.
For our public cloud infrastructure, we’re using a combination of Zabbix and Pingdom to satisfy these different monitoring needs. Both are configured to trigger alerts using PagerDuty, a SaaS alerting service that handles on-call schedules, contact information and escalation plans.
Zabbix is a flexible, open source monitoring platform for operating system and network level metrics. It operates on a push basis, streaming metrics to collectors that aggregate them and provide storage, visualization and alerting. Also—and critically in a public cloud environment—Zabbix supports automatic host registration so that a new node can register with the aggregator with no manual intervention.
Pingdom looks at services from the opposite perspective, i.e., as a list of black boxes that it checks periodically for certain behaviors. If you have carefully defined your SLA in terms of your APIs and their behaviors, then you can create a set of Pingdom checks that will tell you factually whether your service is meeting its SLA, and even create reports based on the historical trends.
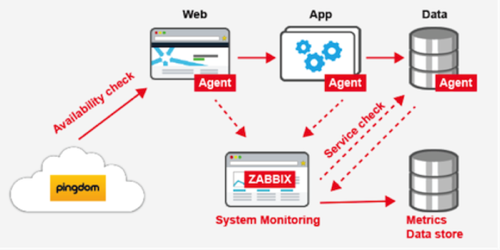
A PaaS also needs another layer of monitoring: internal platform monitoring. The platform checks the health of each running customer app on a periodic basis, and uses the AWS API to replace it automatically if something goes wrong. This makes it so that there is a minimal interruption of service even in the case of a catastrophic failure, because once the app stops responding it is soon restarted. Internal health checks like this are application specific and require a significant technical investment, but provide the best auto-healing and recovery capabilities because the application has the most context regarding expected behavior.
Configuration As Code
It’s also critical to know what your hosts are running at all times, and to be able to spin up new ones or update existing ones at a moment’s notice. This is where configuration management comes in. Configuration management lets you treat configuration as code, committed to GitHub and managed just like any other repo.
For configuration management, the DevOps team at MuleSoft uses SaltStack, a lightweight remote execution tool and file server written in Python and based on ZeroMQ that provides configuration management as an intrinsic feature. Combined with AWS’ CloudFormation service for infrastructure provisioning, this creates a potent tool set that can spin up, configure and run entire platform environments in minutes. SaltStack also provides an excellent remote execution capacity, handy under normal circumstances, but critically valuable when trying to make a sweeping production modification to recover from a degradation of service.
As an aside, the combination of IPython, boto and the Salt Python module provides an amazing interactive CLI for managing an entire AWS account from top to bottom. More about that in a future article.
Low-Risk Deployment
It’s probably painfully obvious to anyone in the software industry, and especially to anyone in DevOps, that the biggest risks and the biggest rewards are always packaged together, and they always come with change. In order to maintain a high rate of change and high availability at the same time, it’s critical to have tools that protect you from the negative consequences of a botched operation. For instance, continuous integration helps to ensure that each build produces a functional, deployable artifact, multiple environments provide arenas for comprehensive testing, and red/black deployment takes most of the sting out of a failed deployment by allowing fast failure and rollback.
We use all of these strategies to deploy and maintain our cloud infrastructure, but the most critical is probably the automated red/black deployment behavior incorporated into the PaaS customer app deployment logic, which deploys a new customer app to the environment, and only load balances over and shuts down the old application if the new one passes a health check. When DevOps needs to migrate customer apps off of failing infrastructure or out of a degraded AZ, we leverage the same functionality to seamlessly redeploy it to a healthy container.
Availability For All
There really is no black magic required in order to set up a redundant, resilient and highly available architecture in AWS (or your public cloud provider of choice). As you can see from our setup, the accessibility of advanced IaaS platform services and high quality open source and SaaS tools allows any organization to create an automated and dependable tool chain that can manage entire infrastructure ecosystems in a reliable fashion.