The Big Data future is here, but isn’t yet evenly distributed, to paraphrase William Gibson. More accurately, what we call Big Data today is what Silicon Valley’s web giants were doing years ago, but it’s considered new and exciting today because the methods and technologies used to power Big Data have been open sourced and have flooded mainstream enterprises.
In conversations with a host of traditional enterprises across Europe, it has become clear there is little that is particularly novel about Big Data, except for its accelerating adoption outside Silicon Valley.
Distributing The Future
I mention Europe because it has tended to lag the US in terms of enterprise IT. Whether we’re looking at cloud adoption or Big Data adoption, Europe is a year or two behind the US. So when I hear European firms talking seriously about Big Data projects, it suggests that Big Data is going mainstream.
Which is not the same as saying “everyone is doing it.” Gartner reports that 42% of IT leaders have dabbled in Big Data projects, which indicates there’s still room to grow. But I suspect the number is actually bigger than 42%, and may have much to do with defining “Big Data.”
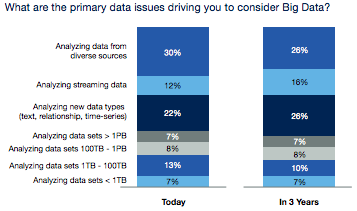
For example, when I ask an IT professional whether she’s launched a Big Data project, quite often she says no. When I clarify that I don’t mean whether she’s running a project that involves hundreds of terabytes or even petabytes of data, but instead involves an application pulling data from disparate sources to yield real-time analytics, much more often she says yes. Such projects are, of course, “Big Data.” But because the term suggests that “big” matters more than “data,” people get confused.
This comes out in a NewVantage survey, which found that a mere 15% of respondents were dealing with hundreds of terabytes of data. Indeed, the primary concern for these survey respondents was the ability to manage a diverse, ever-growing body of data sources. Hence, it’s not surprising that even Hadoop, ostensibly for storage and processing of huge data sets, is much more often used for ETL.
Size really doesn’t matter in Big Data.
Open Source Is Democratizing Innovation
And size is relative, anyway. Much of the reason that Google and Facebook invented things like MapReduce and NoSQL databases was to cope with the demands of real-time data-driven applications. Now those technologies are open source and widely available, to the extent that today’s web giants have moved onto new Big(ger) Data technologies that the rest of us will be using a few years from now.
Hence, ReadWrite‘s Brian Proffitt captures the real value of Hadoop: it made data storage cheap when it had hitherto been expensive. NoSQL didn’t replace relational databases’ role in managing complex transactions but instead enabled a new class of application that required hyper-fast management of semi-structured data, as GigaOm‘s Derrick Harris notes. And across the board, they were born within the data centers of the web giants and then released as open source for the mainstream enterprises to adopt.
For this and other reasons, it seems to me that the best way to define Big Data involves how you’re using data, and has almost nothing to do with the volume of data.
One Old-School Enterprise Becomes New
As an example, one European IT leader with whom I spoke recently noted that he has moved his team from a waterfall development approach to agile development, with 20 to 30 releases per day. The team responds to real-time customer feedback, which is pulled from 3,000 servers and generates 500 GB of new data each day, and can move from development to deployment in 24 minutes.
As he explained it to me, the company determined it needed to move from a “I know what the customer wants and will force it on them” approach to a data-driven model. This required swapping out their rigid data infrastructure, which imposed heavy friction on their ability to change, and it also involved, as noted, a shift to a more agile development approach. The two generally go together.
None of this is novel. Silicon Valley has been operating like this for years. But that’s the point: the traditional enterprise increasingly adopts the development practices and technologies of Silicon Valley’s tech elite. “Big Data” today in the mainstream enterprise is small data for web giants like Facebook.
What will be fascinating to watch is whether more mainstream enterprises—say, Chevron or Kohls—will develop their own Big Data technologies to meet needs that the web giants don’t have. Perhaps innovation will start flowing back toward Silicon Valley …? Time will tell.
Image courtesy of Shutterstock.