Since the advent of big data, it’s been a struggle for some to get a real sense of just how big big data really is. You hear strange terms like “peta,” exa” and “yotta”… but what does all that really mean? When managing massive amounts of data, the scales were talking about can quickly reach astronomical proportions.
Coming from Indiana, where the value of Pi might have once legally been 3, it would be easy to just slap the label “gi-fracking-normous” on the scales we’re talking about, but I’m going to push past my native upbringing and focus on recent efforts to quantify big data. A recent infographic from clearCi is one such effort, outlining the scale of data produced on the Internet each day: 2.5 quintillion bytes of data.

In scientific notation, that number compresses from 2,500,000,000,000,000,000 to 2.5X1018 – or 2.5 exabytes. To try to scale this, clearCi’s graphic estimates that if each byte was a bucket of water, in 20 weeks, there would be enough data produced to fill every ocean on the planet.
That’s assuming the rate of data produced remains steady, and there’s little evidence of that. Just four years ago, all of Google was cranking out 20 petabytes of data per day – think a 2 with 16 zeros trailing it. Today, just the data from Google’s Street View Cars is the equivalent of 20 petabytes.
The Powers Of Ten
The scales that we’re talking about are ridiculously large, and not easy to grasp, which leads to clever little analogies that try to put it in terms that we can kind of understand. In that spirit, I referenced the best visual aid I know to relate scale: Powers of Ten, the 1968 short film that even now conveys scale very well. If you have never watched this nine-minute film, avail yourself.
Using the same scale model as this clever movie, and thinking of one byte as equal to one square meter in area, scale of data becomes a little bit easier to envision. (A note before the pedantic come out of the woodwork: I know darn well that a kilobyte isn’t 1,000 bytes, but rather 1,024. But I’m keeping it metric for the purposes of this demonstration. So there.)
A kilobyte translated to meter-scale would be 1,000 square meters, or 1 square kilometer. Easy enough.
A megabyte is a thousand times bigger, or one million square kilometers. That would be a square just about enough to encompass all of the Great Lakes in the United States.
Multiply that by another thousand and you get into gigabyte territory. In terms of square meters, that’s a square big enough to surround the entire Earth-Moon system.
Terabytes get pretty big… at one byte/sq. meter, a terabyte square would completely bound the inner Solar System with some edges crossing the orbit of Jupiter.
Petabytes at this scale are really big; the square is now big enough to encompass the entire Solar System nearly 100 times over.
Exabytes, which is now the scale where the Internet’s daily production lives, would be a square nearly 100 light years on each edge if every byte filled a square meter. So imagine two-and-a-half of those squares being filled every day and you can get an idea of the kind of numbers we’re talking about. Storage vendor Seagate figures that a total of 450 exabytes of storage shipped in 2011.
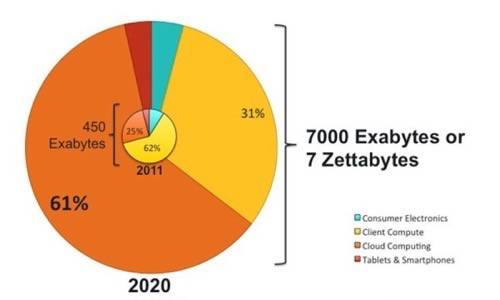
There’s more, or course. Scale up another thousand times and you have the zettabyte, which is 1021 (a one followed by 21 zeroes) bytes. That square would be completely filled by our Milky Way Galaxy. Seagate goes on to estimate that by 2020, total demand for storage will be just about 7 zettabytes’ worth of capacity.
Yottabytes are at 1024 scales, which is where the Powers of Ten movie and, coincidentally most big data conversations, stops. Such a square would easily surround the Local Supergroup of galaxies, in which our own galaxy would appear to be a fuzzy star.
How Big Can Data Get?
It will get bigger, of course. The next level of data will be the brontobyte, which is 1027 bytes. While the Powers of Ten movie stopped at yottabyte levels, there’s another useful comparison for the brontobyte scale. It’s estimated that the human body contains 7 octillion atoms. If each atom were a byte of information, that’s 7 brontobytes of data.
No one company, not even Google, will every get to the upper ends of these scales. But with terabyte amounts of data an everyday occurrence and petabytes not so rare anymore, a lot of companies will need to wrap their heads around the notion of what the big in big data really means and bring it down to Earth.
Images courtesy of European Space Agency, clearCi, and Seagate Market Research & Competitive Intelligence.