
With the right data, you can get a pretty interesting picture of an area. Whether it’s a state, city, or even a street, you can learn a lot from data. Do you need to pack a coat if you’re visiting in March? What’s the elevation, cost of living, how many people live there? But to answer what is it like? That takes a bit more doing.
This was the topic of Jesper Andersen’s talk at Strata, “Building a Data Narrative: Discovering Haight Street.” The idea, to “see how far we can go” in understanding San Francisco’s famous Haight Street through as much data as possible.
Tell Me a Story
Before diving into the data, Andersen made the case for providing a narrative for Haight Street. Pure numbers work for some types of data, but they’re not good at expressing social networks or explaining what a street is “like.” For example, Andersen talked about Klout and the way it tries to express a person’s social influence with a number. Klout, says Andersen, “is reductive and destroys value” in trying to sum up a person’s social network with a single number.

Andersen didn’t spare himself, either. He talked about some of his former work with Visible Path creating a “horrible interface I’m now ashamed of.” The problem, says Andersen, was trying to reduce users to scores. “Don’t give users scores, give them stories.”
So how do you create a story from the data available for Haight Street? Andersen noted that you can find a lot of data about Haight Street, but when you search WolframAlpha about Haight Street you don’t really get to know the street.
What you get is cold facts. A map that shows Haight Street as perfectly straight, but doesn’t give the elevation. It certainly doesn’t give the atmosphere of the street. To dive in to find out what the street is like, Andersen delved a bit deeper.
For example, he looked into Foursquare checkins, and mapped them along the length of Haight Street and compared them to a map of the elevation of Haight Street. He took Google Street View and tried to extract the colors of Haight Street to see what the primary colors of Haight Street are.
Andersen tried to answer questions like “where is it safe?” using DataSF.org and looking at the crime statistics. Again, he mapped these according to the length of the street and compared upper and lower Haight Street. (Lower Haight Street is less safe, statistically.)
What Are the People Like?
The hardest of questions? “What are people like on Haight Street?” To try to puzzle this out, he looked at Twitter data by location and language. Surprisingly, you’ll find a lot of Swedish folks on the upper half of Haight Street. Not surprisingly for San Francisco, many people on Haight speak Spanish or Japanese.
Andersen also tried sentiment analysis of Tweets and found that, by distribution, people were more negative on the lower half of Haight. He was also able to get some idea of what people found interesting on Haight by mapping pictures from Instagram to the street as well.
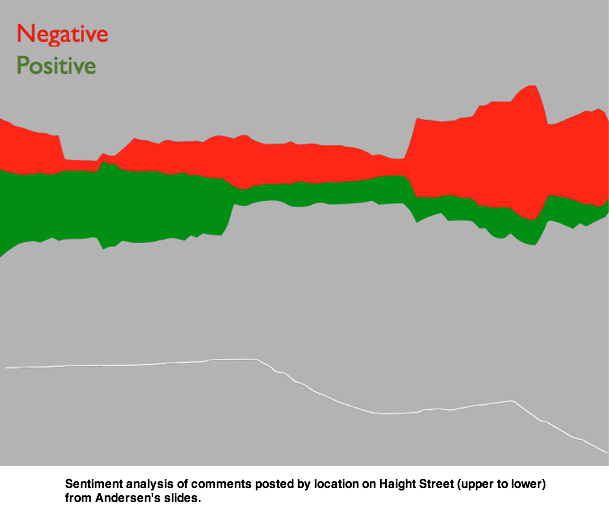
All of this information is out there, and can be used to start telling a story about a location past hard facts. It’s not a perfect picture, but it’s a start towards storytelling with data instead of just a jumble of numbers and facts that don’t paint much of a picture at all. Andersen’s attempt suggests that there are ways to use existing data for storytelling. What’s more, there could be a big opportunity for app makers to look for new ways to collect and display data to paint better pictures of real life.
Haight Street photo courtesy of Wikipedia under the (CC BY-SA 3.0).









{kind=link}