











The astonishing speed at which the “big data” processing industry is evolving dwarfs anything we’ve ever seen with regard to software. Problems that stymied the best engineers just 18 short months ago are now commonplace tasks for modern data centers. Already, the systems envisioned by Google’s and Yahoo’s engineers are being prepared for the history books, as 2012 should bring forth the second generation of open source, scalable, big data processing.

Which is why MapR Technologies’ release this week of the next distribution of MapR – which includes a commercial implementation of Hadoop called M5 – is important, not for what it will do today, but for what it will enable tomorrow: Hadoop is gearing up for a kind of liver transplant, if you will, in the upcoming version 0.23.
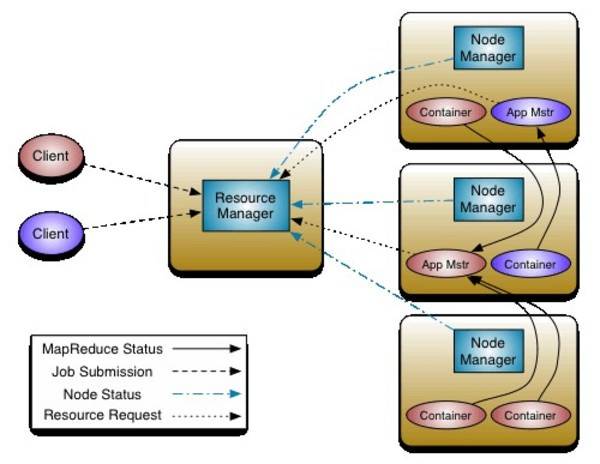
The division of resources and nodes into two tiers in Hadoop 0.23. [Chart by Apache Software Foundation.]
The Hadoop system splits huge database tasks across multiple nodes in a data cluster. In this system, it’s MapReduce’s job to process data in parallel batches, and return results that are effectively mathematical “reductions” of those batches. In the old Hadoop architecture (where “old” in this instance means weeks and weeks ago), the process that monitors and marshals the progress on these parallel batch jobs was called JobTracker. Since its implementation, engineers have realized that it would be better to think of jobs not as “lumps” of processes, but instead more like an operating system: with a ResourceManager that manages addressable resources in a cluster, and an ApplicationManager that marshals the use of those resources.
It’s a fundamental rethinking of Hadoop architecture; and because the tools that implement Hadoop today are still (relative to a real-world clock) new, rolling out this change is liable to upset the balance of things in some data centers. Imagine inserting pecans into the middle of a mold of Jell-O that’s already half-set, and you’ll get the idea.
One of MapR’s key innovations was originally around a high availability (HA) implementation of JobTracker. It takes into account the fact that processes fail, so that when a JobTracker does crash, MapR can spin a new one and attach the existing TaskTrackers to it before they’ve noticed anything’s happened at all. Since it’s JobTracker that’s getting the axe, the new MapR 1.2 will prepare data centers for the time when that HA capability will need to spin a new version of ApplicationTracker instead.
Also, MapR has historically replaced Hadoop’s crude, write-once distributed file system (HDFS) with a direct-access, lockless storage system based on Sun’s pre-established Network File System (NFS) protocol. Another key feature of a future Hadoop distribution is HDFS federation, effectively sharing the file system with multiple, distributed nodes. This won’t actually help MapR much, if at all, although it may conceivably introduce a problem with compatibility that MapR 1.2 may also address.
As MapR Chief Application Architect Ted Dunning explained to a customer who questioned the benefits of HDFS federation, “The problem of reliability just get worse with federation because the previous single point of failure is multiplied. Looking only at hardware reliability, if you have ten name nodes, the mean time between hardware failures for your cluster is likely to decrease to a few months down from the current level of a few years. Of course, human fallibility normally increases these failure rates significantly. MapR addresses both hardware and human failure modes and also provides much higher scalability than Apache Hadoop.”
MapR’s Hadoop distributions are classed as M3, which is both free and 100% compatible with Apache Hadoop; and M5, which contains all of MapR Technologies’ commercial innovations.




















