
How do three guys with only seed funding process a hundred million messages a day? I sat down with the BackType team to discover how they built a service relied upon by companies like bit.ly, Hunch and The New York Times.

BackType captures online conversations, everything from tweets to blog comments to checkins and Facebook interactions. Its business is aimed at helping marketers and others understand those conversations by measuring them in a lot of ways, which means processing a massive amount of data.
To give you an idea of the scale of its task, it has about 25 terabytes of compressed binary data on its servers, holding over 100 billion individual records. Its API serves 400 requests per second on average, and it has 60 EC2 servers around at all times, scaling up to 150 for peak loads.

Christopher Golda

Michael Montano

Nathan Marz
It has pulled this off with only seed funding and just three employees: Christopher Golda, Michael Montano and Nathan Marz. They’re all engineers, so there’s not even any sysadmins to take some of the load.
Coping with that volume of data with limited resources has forced them to be extremely creative. They’ve invented their own language, Cascalog, to make analysis easy, and their own database, ElephantDB, to simplify delivering the results of their analysis to users. They’ve even written a system to update traditional batch processing of massive data sets with new information in near real-time.
The backbone of BackType’s pipeline is Amazon Web Services, using S3 for storage and EC2 for servers. It leverages technologies such as Clojure, Python, Hadoop, Cassandra and Thrift to process this data in batch and real-time.
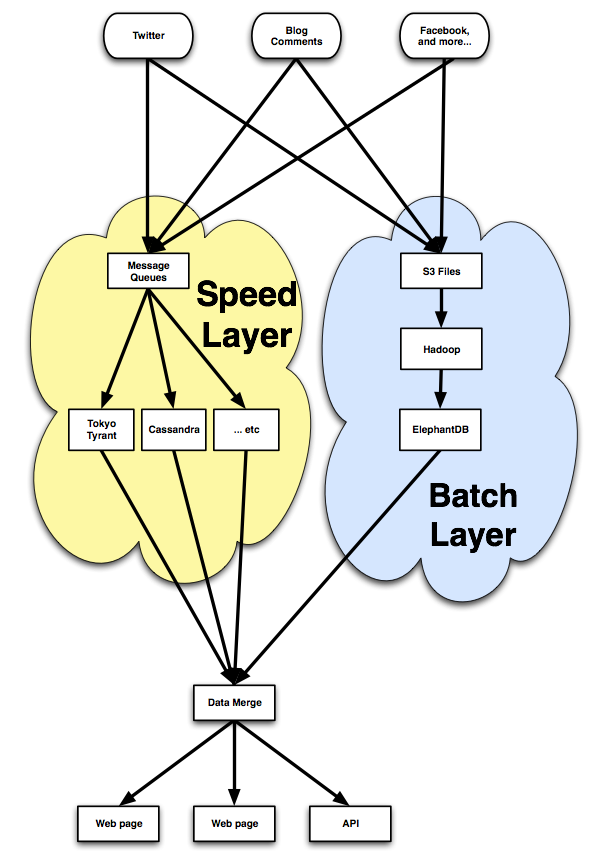
The start of the pipeline is a group of machines that ingest data from the Twitter firehose, Facebook API and millions of sites and other social media services. The first interesting feature of the architecture is that it actually has two different pipelines, one the traditional batch layer that takes hours to produce results, and a “speed layer” that reflects new changes immediately.
Captured data is fed into the batch layer through processes on each machine called collectors. These append new data to a local file, which is then copied over to S3 periodically. This raw data is then put through a process they call shredding, which organizes it in two different ways. First, data units are stored with others of the same type. For example the content of tweets or blog comments would be stored together and separate from the names of their authors. Second, the same data is sliced by time, so everything within a single day will be stored together.
Why do they do this? The organization of the data enables them to run more efficient queries only against the relevant data. When they have a job that requires analyzing Twitter retweets for example, they can just pull out the content, sender and time for each message, and ignore all other metadata. This process is made a lot easier thanks to their use of Thrift for the data storage. Everything in their system is described by a graph-like Thrift schema, which controls the folder hierarchy the data is stored into, and automagically creates the Java/Python/etc code for serialization.
Cascalog is one of their secret weapons, a Clojure-based query language for Hadoop that makes it simple for them to analyze their data in new ways. Inspired by the venerable Datalog, and built on top of Cascading, it allows you to write queries in Clojure and define even complex operations in simple code. Unlike alternatives like Pig or Hive, it’s written within a general-purpose language, so there’s no need for separate user-defined functions, but it’s still a highly-structured way of defining queries.
Its power has enabled them to quickly add features like domain-level statistics and per-user influence scores with just a couple of screens of code. It’s spread beyond BackType and has an active user community including companies like eHarmony, PBworks and Metamarkets.
The final part of the batch processing puzzle is how to get the results of your analysis to the final user. They experimented with writing out the data to a Cassandra cluster, but ran into performance issues. What they ended up creating instead was a system they call ElephantDB. It takes all the data from a batch job, splits it up into shards, each of which is written out to disk as BerkeleyDB-format files. After that they fire up an ElephantDB cluster to serve the shards. Unlike many traditional databases, it’s read-only, so to update data served from the batch layer you create a new set of shards.
So that’s how the heavy processing is done, but what about instant updates? The speed layer exists to compensate for the high latency of the batch layer. It is completely transient and because the batch layer is constantly running it only needs to worry about new data. The speed layer can often make aggressive trade-offs for performance because the batch layer will later extract deep insights and run tougher computations. It takes the data that came in after the last batch processing job and applies fast running algorithms.
Because the Hadoop processing is run once or twice a day, the fast layer only has to keep track of a few hours of data to produce its results. The smaller volume makes it easy to use database technologies like MySQL, Tokyo Tyrant and Cassandra in the speed layer. Crawlers put new data on Gearman queues and workers process and write to a database. When the API is called, a thin layer of code queries both the speed layer database and the batch ElephantDB system, and merges the information from both to produce the final output that’s shown to the outside world.
BackType isn’t the only startup to split its processing using this combination of speed and batch layers; Hunch does something similar for its user recommendations. The trouble is that nobody has found an approach that is as elegant or generally applicable as MapReduce for real-time processing of continuous streams of data.
Yahoo’s S4 “Distributed Stream Computing Platform” is an interesting start, but Marz explained that they weren’t able to build on top of it because it didn’t offer any reliability guarantees, thanks to its use of UDP for communication. The lack of unit tests also made it daunting, since it would be tough to spot if any modifications they needed to make had introduced subtle bugs.
Instead of the firefighting and housekeeping burden I’d expect from such a complex system, they seem to spend most of their time focused on applications that solve customer problems.
Instead, Marz and Montano have been working on a new framework based on their own experiences. The technology managing the streaming processing and guaranteeing reliability of messages is called Storm, and though it can run a variety of languages, they’ve designed one especially for it called Thunderlog, based on Cascalog.
Though they are not yet ready for release, Storm and Thunderlog are being actively developed and will soon replace their more hand-coded speed layer. The system will incorporate many of the tips they picked up building their first system. For instance, to avoid concurrency issues without paying a performance penalty, you can group events by key so that possibly conflicting changes happen on the same machine in a serial fashion.
At the end of the tour of their technology, I was left very impressed by how much they have accomplished with so few engineers. Instead of the firefighting and housekeeping burden I’d expect from such a complex system, they seem to spend most of their time focused on applications that solve customer problems.
The secret is their ability to automate the routine tasks with tools like Cascalog, ElephantDB and Thunderlog. Writing those allows them to spend their limited time on writing new applications that offer direct value to their users, without having to wrestle with screenfuls of boilerplate code first. They are on the lookout for new team members, and say they’ve only stayed so small because they are so committed to only hiring the very best. If you’re interested in working on the cutting edge of big data processing, drop them an email at [email protected].








