
InfoQ has released a video of Twitter‘s Kevin Weil speaking at Strange Loop earlier this year on how the company uses NoSQL. Weil is quick to point out that Twitter is heavily dependent on MySQL. However, Twitter does employ NoSQL solutions for many purposes for which MySQL isn’t ideal. According to Weil, Twitter users generate 12 terrabytes of data a day – about four petabytes per year. And that amount is multiplying every year. Read on for our notes on Weil’s talk.

Scribe
Syslog stopped scaling for Twitter after a while, so instead it uses Scribe, a log collection framework created and open-sourced by Facebook. Twitter has contributed some of its own patches to Scribe.
Twitter uses Scribe to write logs to Hadoop. Scribe made it so easy for Twitter to log data, it started to log much more data. It now logs 80 different categories of data.
Hadoop
Twitter needs to store more data per day than it can reliably write to a single hard drive, so it needs to store data on clusters. Twitter uses Cloudera‘s Hadoop distribution to power its clusters.
Weil says MySQL isn’t efficient at doing analytics at the scale Twitter needs. Instead, Twitter uses Hadoop and its own open-source project called FlockDB. Hadoop can run analytics and hit FlockDB in parallel to assemble social graph aggregates.
Pig
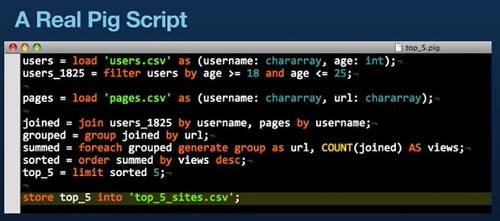
This Pig script finds the top five pages of your site visited by people aged 18 to 25.
Weil says the most natural way to “talk to” Hadoop is through Java. But Java is complex and makes it hard to rapidly iterate. Instead, Twitter uses Pig, a high-level language running on top of Hadoop. Yahoo created Pig for rapid Hadoop development, and Weil says it’s very easy to learn and understand. He says you pay for Pig’s convenience with some reduced execution time, but that it’s worth it.
Hbase
Hbase is built on top of Hadoop and is designed for low-latency and data mutability. Twitter uses it to power its people search.
FlockDB
FlockDB is a real-time, distributed database. As mentioned above, it was created and open-sourced by Twitter. The company uses it for social graph analysis. It’s still MySQL underneath, but it’s very fast.
One application of FlockDB that Weil cites is determining which users to show @ replies to. For example, if Ashton Kutcher sends a tweet to @foursquare, it shouldn’t show up for all of Kutcher’s 6,156,915 followers. It should show up only for users that follow both Kutcher and Foursquare.
Weil cites this SlideShare as a resource for those wanting to know more about how Twitter analyzes social graphs:
Big Data in Real-Time at Twitter
View more
from
.
Cassandra
Twitter is still experimenting with its use of Cassandra, an open-source NoSQL database created by Facebook. Weil says Twitter is currently experimenting with using Cassandra for atomic counting.
What Does Twitter Do With All This Data?
Twitter uses all the data it collects for a variety of purposes. Some are just simple counting problems, such as figuring out how many requests it serves a day, how many searches it serves a day, what the average time it takes to process those transactions is, etc.
Other uses are more complex. For example, running comparisons of different types of users. Twitter analyzes data to determine whether mobile users, users who use third party clients or power users use Twitter differently from average users. The company is also interested in determining whether certain features or occurrences trigger a casual user into becoming a frequent user. For example: do people become frequent users when they start following the right people or discover the right feature?
Other questions Weil says Twitter is interested in include determining which types of tweets get retweeted the most, what types of social graph structures result in the most successful networks and how to tell the difference between humans and bots.
More NoSQL Resources
Still confused about how different NoSQL solutions are used? Here are some more resources:








