The soccer World Cup has now ended, with Spain the victor. England was unceremoniously dumped out before the quarter finals – but if there was a World Cup for the Semantic Web, then the BBC may have lifted the trophy for its country. A post on the BBC Internet site explains how the BBC World Cup 2010 website used “dynamic semantic publishing” technology.

It’s an impressive demonstration of how a large, mainstream website can have added meaning and structure.
ReadWriteWeb’s Guide to The Semantic Web:
The BBC World Cup site featured over 700 webpages and was powered by a semantic publishing framework. The site boasted a comprehensive ontology (a map of concepts), that output “automated metadata-driven web pages” created on-the-fly.
Jem Rayfield, Senior Technical Architect, BBC News and Knowledge, explained further:
“The underlying publishing framework does not author content directly; rather it publishes data about the content – metadata. The published metadata describes the world cup content at a fairly low-level of granularity, providing rich content relationships and semantic navigation. By querying this published metadata we are able to create dynamic page aggregations for teams, groups and players.”
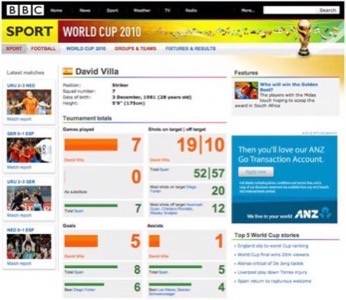
The basis of this system was an ontology that described how World Cup facts related to each other. For example, “Frank Lampard” was part of the “England Squad” and the “England Squad” competed in “Group C” of the “FIFA World Cup 2010”. The ontology also included “journalist-authored assets” such as stories, blogs, profiles, images, video and statistics.
The publishing platform had both manual and automated tagging features. BBC journalists could, for example, tag Frank Lampard in a story about the disallowed goal from England’s last-16 loss against Germany. This is a normal part of most modern-day publishing systems (we tag content in this manner here at ReadWriteWeb). But the BBC World Cup site also automatically analyzed journalist content and matched it “against the World Cup ontology.” It did this by using what it describes as a “natural language and ontological determiner process.” [Update: IBM wrote in to inform us that the technology behind this was IBM LanguageWare.] This is similar to software such as Thomson Reuters’ Calais or the new Extractiv product that we reviewed yesterday. In the BBC’s case, the resulting tags were moderated before being published.
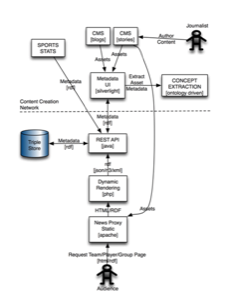
The BBC used Semantic Web technologies such as RDF and SPARQL to build their World Cup site. The stated goal was to achieve “intelligent mapping of journalist assets to concepts and queries.”
The site reportedly served millions of page requests a day throughout the World Cup. The BBC may use this semantic publishing platform for other parts of the BBC sports site; and it will certainly deploy it again for the the London 2012 Olympics.
The official explanatory post has the technical details, should you wish to follow up. Let us know in the comments about other large scale Semantic Web deployments that you know of.
Update: See also The World Cup and a call to action around Linked Data, by the BBC’s John O’Donovan. Thanks Georgi Kobilarov for the pointer.

















