
Twitter announced yesterday that it would begin offering parsed and structured data via its API that will likely lead to a slew of new Twitter tools and ways of extracting information from tweets.

Until now, Twitter developers had to work with individual tweets on their own, pulling out hashtags, @ mentions, links and other such data. With this latest addition to the Twitter API, however, this information will be handed out in easily digestible bites. One such use might be the improved search results we’re seeing on Twitter that Sarah Perez just wrote about below.
The announcement came yesterday from Twitter platform developer Raffi Krikorian by way of the microblog’s API Google group. According to Krikorian, “something like 50% of tweets” contain at least one @mention, list mention, URL or hashtag.
Developers who want to understand the tweet text have to parse the text to try to extract those entities (which can get really hard and difficult when dealing with unicode characters) and then have to potentially make another REST call to resolve that data.
The functionality had been available previously via Twitter internationalization team member Matt Sanford as the Twitter-text library on github. As of now, however, this parsing of tweet data will become part of the JSON and XML payloads provided by Twitter’s API, which means we’re likely going to see a lot more developers including functionality using this information.
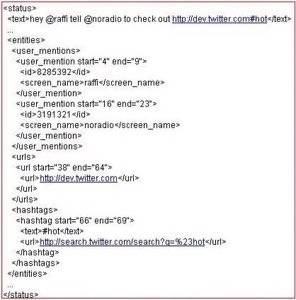
As you can see in the example we’ve included here, the new structured data format will include a unique ID, string location and other data for each “entity”. Before this was added to Twitter’s API, the onus was on the developer to parse out the string. The new feature should not only promote new features and mashups, but should likely lead to more efficient storage of data and more fruitful results to queries.
Another point to remember is that this ought to lighten the load on Twitter’s API, even if just by a tiny percentage, as programs will have to make fewer API calls.








