
Collaborative Filtering (Wikipedia definition) is a mechanism used to filter large amounts of information by spreading the process of filtering among a large group of people. Unlike mainstream media where there is either one or very few editors setting guidelines, the collaboratively filtered social web can have infinitely many editors and gets better as you increase the number of participants.

There are two basic principles involved in Collaborative Filtering.
1. The Wisdom of Crowds and Law of Large Numbers suggest that as communities grow, not only does a large (diverse, independent, etc.) community make better decisions than a handful of editors, but the larger a community gets, the better its decisions will be. Therefore, we can hypothetically create a Collaboratively Filtered newspaper, television channel, radio station, etc., which would be better (for the community) rather than any other arbitrarily selected medium. In fact, as we will see, services like Digg, YouTube, and Last.fm, are trying to do exactly that – (CF) based media outlets.
2. The second principle of Collaborative Filtering suggests that in any such large community, with enough data on individual participants and on how the individual participants collaborate or correlate with each other, we can make predictions about what these users will like in the future based on what their tastes have been in the past, i.e. develop a collaboratively filtered recommendation engine. This, of course, relies on the fact that people’s interests, preferences, and ideologies don’t change too drastically over time.
The two aspects of the (CF) system result in two very different and important results.
The first gives you new, interesting, entertaining, and newsworthy information as judged by the community (in a way this is content that is the average of the interests of the entire community) and a good example of this is Digg’s front page. Not all the content will be directly relevant to your tastes and in fact some of it will be completely irrelevant to you. However, as the community grows and becomes more diverse and independent, the average news story promoted to the front page will be of interest to the average community member. Not satisfied with averages? This is where the second aspect comes into place.
The second aspect of the (CF) system collects information on what kind of content and commentary you like and dislike, and based on your submission and voting habits, it does user-data-profiling. This user profile helps the site recommend content that has been submitted by users (or from sources) you generally agree with and find interesting, as well as topics that you usually vote up and tend to comment on. What this means is that by collecting enough information on how you interact with the site and with other users, the (CF) system can recommend content to you. The system finds the content and deliver it to you rather than it requiring you to scout for it. Furthermore, the more you use the recommendation system and vote up or down, the better it becomes with its recommendations.
The important thing, one that not many social sites realize, is that a (CF) system that doesn’t automatically match content to your preferences, is inherently flawed. The reason for this is simple: Unless you can achieve perfect diversity and independence of opinion, one point of view will always dominate another on a particular platform. The dominant point of view on the social web is a left-leaning one, and without the ability to get the most appropriate pieces of content to the people that care most about them, the right-wing point of view gets buried almost every time.
A perfect example of this was the Ron Paul supporters and the ease with which they were able to manipulate the social news sites. Now if you could match the right-wing viewpoint to the right-wingers, and the left-wing viewpoint to the left-wingers, and get both points of views across to people that are interested in healthy debate rather than partisan politics, you’re getting closer to the ideal system. A filtering system with preference-based recommendations, in essence, is the future of the social web.
Who is using what system?
The (CF) system is without a doubt the lifeblood of the social web. Even though different platforms apply it to varying extents, the system is still there at the core, and the social web would look more like rush hour in downtown Lahore if the community wasn’t actively policing the traffic.
Social News
In the social news space, Digg and Propeller just use the system insofar as the front page is concerned (although Digg is set to release their recommendation engine this week). Once the content is promoted to the front page, the system’s job is done. The system works in that you get rid of spam and unoriginal thought, but it isn’t the best because it relies on averages rather than direct preferences of each participant. While these sites try to catch up and develop recommendation engines of their own, Reddit and StumbleUpon have leapfrogged them for a while now by having recommendation engines in place. These two sites also have similar concepts of a community front page (based on the average interests of the average community member) but they enhance your experience and incentivize increased participation by using your history of likes and dislikes to deliver the most high-quality and most relevant content to you. Furthermore, the normalization of Reddit’s front page shown how a one-front-page-for-all approach forces conformity and dilutes the individual experience, whereas normalization ensures that each user controls how content is distributed to him or her.
Ultimately, even though there are some sites with little or no filtering (Slashdot, Fark, etc.), sites that use their (CF) based recommendation engines will continue to diminish the importance of active filtering from upcoming submission queues and improve the quality of user experience on an individual level.
Video Streaming and Sharing
Online video sites hosting and sharing sites are not much different. Site’s like YouTube have multiple filtering mechanisms that often perform the same functions without requiring votes per se. Viewability, for example, is determined by:
1. Number of people currently watching a video
2. Number of comments on a video
3. User ratings and favorites.
The problem with impressions-based system (like the one used by now understandably dead content aggregator Spotplex) is that just because you viewed something or commented on something doesn’t mean that it’s good. In fact, there are dozens of YouTube videos that I click on, don’t like them and then close the window (I see other people writing negative comments in poor English but I doubt that helps either). Some other sites like Break and Funny or Die use a StumbleUpon-like up/down voting system to determine what gets promoted to the front page. Again, while there are options to view similar/related videos and more videos from a user you like, there is no recommendation system using your rating and favoriting habits (and tags you like).
Blogging and Microblogging
For the most part, blogs use a combination of most viewed, most linked, most commented, and highest rated, as mechanisms for displaying content that you might like. While this is a better idea than letting people go through trial and error, it doesn’t ensure that every visitor will be happy with what they see. For example, two very different posts on two entirely different topics can be the most viewed posts on your blog, and I might like one and not like another. At the same time, one has to wonder, at what point is it economical or time-efficient to start monitoring each individual user?
StumbleUpon solves this problem for the ‘big guys’ by letting you StumbleThru one site for the content that you might like the most. The feature, however, is not available for all sites yet.
Most Microblogging sites, unfortunately, have no filtering system at all. The signal to noise ratio debate rages on with respect to Twitter and its ilk. FriendFeed, however, launched a rudimentary recommendation feature that simple displays the top ‘liked’ and commented links.
Photo Hosting and Sharing
When I was thinking about the concept of (CF) systems, photo-sites like Flickr and Photobucket weren’t even on my radar. Part of the reason for this is how most people I know use these sites, i.e., primarily for hosting and sometimes for finding creative commons images for embedding on their sites. I was, however, quite pleasantly surprised to see that Flickr has gone a long way to help people explore and discover excellent photography.
The feature that most people are probably familiar with is Interestingness. The feature is quite robust. It takes into account things like where the referral traffic to the image is coming from, who is commenting on it and when, who marks it as a favorite and how many people like it, among other more nuanced things. But in addition to that, the site also has other great features such as exploring based on geotagging on a map of the world, popular tags, subject-based and quality-based groups, camera finder, and most recent uploads.
The only thing left to add is a ‘photos you might like’ based on photos you have liked and commented on.
Music Streaming and Discovery
The best implementations of a Collaborative Filtering (CF) system along with a preference based recommendation/discovery system that I have seen are always on music streaming and discovery sites. The implementation on Last.fm for example, is almost perfect in my opinion. First of all, whether you use their online streaming widget or use their desktop software, they monitor every single song you listen to and aggregate that data. They also track how artists jump on and fall off your radar on a week to week basis. They use that data to make specific recommendations and automatically create a radio station for you that plays Last.fm’s recommendations for you based on what you like.
While that in itself is more than enough, they don’t stop there. They have another radio station for you that plays songs you usually like to listen, they show you what the entire Last.fm community is generally listening to, what your friends are listening to, and what your friends are recommending. It is a very robust system for aggregation, filtering, and recommendation. Here’s how the recommendation engine works:
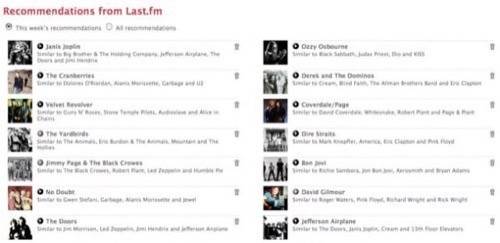
As you can see, they look at the musicians I listen to a lot and then recommend people that are either similar in sound or people who were influencers of or influenced by my favorites. These are followed by recommendations from friends and music-based groups on the site.
So, collaboratively filter and recommend or die?
These are only some of the major players that have embraced (CF) and personalized recommendations – Netflix and Amazon come to mind among others. As you can see from above, it is certainly possible to have a good collaborative filtering system without a recommendation engine (as seen in Flickr). It is optimal, however, for the users (because their experience is better) and your site (because users will participate more often and generally be happy with your product) if you throw in some recommendation system a-la Last.fm, the most robust of the lot by far.
This is a guest post by Muhammad Saleem, a social media consultant and a top-ranked community member on multiple social news sites. You can follow Muhammad on Twitter.









