For a few years now people have been talking about semantic search.
Any technology that stands a chance to dethrone Google is of great interest
to all of us, particularly one that takes advantage of long-awaited and much-hyped semantic technologies. But no matter how much progress has been made, most of us are still underwhelmed by the results.
In head-to-head comparisons with Google, the results have not come out much different. What are we doing wrong?

For example, when asked,
What is the capital of France? both approaches come back with the correct answer – Paris. Also, a lot
of queries that we are used to typing into Google in abbreviated form, come back with similar results if we type them
using natural language. Clearly something is off. We all know that semantic technologies are powerful, but how and why?
In this post we will show that the problem is that we are asking wrong questions.
The mistake is that semantic search engines present us with Google-like search box and allow us to enter free form queries.
So we type the things that we are used to asking – primitive queries. It never occurs to us to type in What actor starred in both Pulp Fiction
and Saturday Night Fever? or What two US Senators received donations from a foreign entity? We type simple questions,
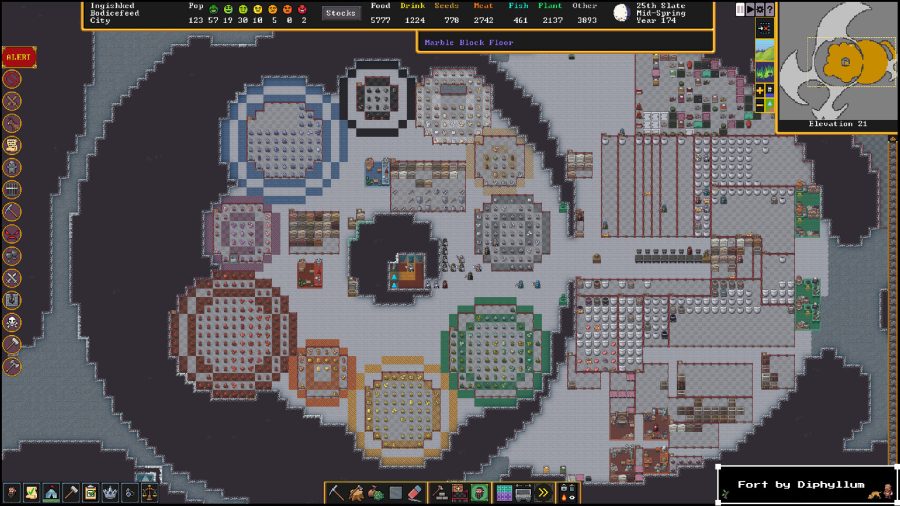
but this is not where the power of semantic search lies. Lets look at the spectrum of semantic technologies from
Google, to SearchMonkey, to Powerset, and Freebase to understand what is going on.
What Problem Are We Trying to Solve?
The first confusion in the space comes from the fact that semantic search is
being positioned as the answer to all possible problems – from modern search, currently dominated by Google,
to problems that are computationally impossible. The situation is made more difficult by the fact that
right now there is only a thin range of problems where semantic search can clearly do better. This range is
complex queries involving inferencing and reasoning over a complex data set.

As shown in the diagram above basic queries are easily handled by Google. Sadly, natural language
processing gives little advantage when it comes to this category of problems. Google correctly
answers the question about Leonardo Da Vinci’s birthday leaving no opportunities to improve
the search by understanding the nouns and the verbs that user typed in.
Before looking at the problems that are perfect for semantic search, lets look at the hardest problems.
These are computationally challenging problems that really have nothing to do with understanding semantics.
The misconception has been perpetuated since early days of the Semantic Web that somehow, because we will annotate
the web, we will be able to solve these super complex problems. This is simply not true. There are fundamental
limits to what we can compute, and a class of problems that have an exponential number of possible solutions
is not going to be magically solved because we represent data as RDF.
The good news is that there is a set of problems that are great for semantic search. These are the problems we have been solving so wonderfully with relational database. Way too often we
forget that semantic technologies are here to help us represent relational data spread over the entire web – so it
should be no surprise to us that it is relational queries that semantic search engines would excel at.
The Spectrum of Semantic Search Players
But semantic search is not just about the questions that we are asking. Because the web is just a bunch of
unstructured HTML pages, semantic search is also about the underlying data. At its most structured extreme we find
Freebase – the semantic database of everything. Freebase is accessible via
free text search, but more importantly via MQL (Metaweb Query Language). MQL is essentially JSON with wildcards.
Using it you can construct any query against Freebase and the result will be the same query with answers filled in.
Powerset, in a way, is just a relational database. It operates against certain, structured information.
On the other end of the spectrum is Google, which is all about statistical frequencies and very little semantics.
The recently launched SearchMonkey from Yahoo! is an interesting twist. It does not add anything to the result set, but instead uses semantic annotations to
present a richer, more interactive and useful user interface.
Companies like Hakia and Powerset are probably working the hardest. These companies are
trying to simultaneously build Freebase-like structures on the fly and then do natural language
queries on top of them. The difference is that Hakia is using (likely similar) technology to query over
the entire web, while Powerset has (probably shrewdly) chosen to restrict the search to Wikipedia.
Are Hakia, Powerset and Freebase All That Different?
This analysis brings up a question – which of these technologies are different and which are essentially
the same? Lets get the easy one down first. Yahoo!’s SearchMonkey is no different from Google or any other search,
as far as the core search technology is concerned. The difference is simply in the presentation layer.
SearchMonkey is smart about creating a better user experience by letting publishers present the search results
to the users in the best possible way.

But when it comes to Hakia, Powerset and Freebase the situation is much more complicated.
On the surface all these products are different – Hakia lets you search the whole web, Powerset is restricted
to Wikipedia (and Freebase!) and Freebase itself has two search interfaces – the search box and query language.
Here is the problem – the natural language interface has nothing to do with the underlying data representation.
The fact is that all of these semantic search technologies allow people to type in arbitrarily complex questions
and then interpret these queries and execute them against their databases. Fundamentally, Hakia, Powerset, and Freebase
are databases. Fundamentally, all of them have some kind of Natural Language Processing that translates the question
into a canonical query over the database.
To gain insight into all of this, think about Freebase and its query language MQL. Unlike natural language,
which allows all sorts of constructs, MQL is non-ambiguous. This JSON-like language allows users to construct precise
statements against Freebase. The fact that Powerset allows natural language queries does not mean that inside Powerset there is no database. For sure, though, there is a similar kind of database as there is beneath the Freebase search box. What is really different
about Freebase and Powerset is the data gathering approach and user experience.
Back to the Future: It’s All About UI
Probably the most striking revelation about the semantic search space is User Interface.
First, to go on the tangent, Powerset got it right by realizing that semantics needs to be surfaced in the UI.
After a user searches Powerset, a contextual gadget, aware of the semantics of the results, helps the user complete the
search experience.
Yet the biggest mistake that I think Powerset is making is also in the UI. The search box that everyone is familiar with via traditional web search engines needs to go. Having a simplistic search interface hurts Powerset and Hakia, and
to a lesser extent Freebase, which is not positioning itself as generic search.
Think about the recent launch of Powerset.
The company released a vastly better way to interact with one of the most important sources of information
on the web – Wikipedia. But what did the critics say? Lets see if this is a Google killer. And the answer to that is “no.”
But what if Powerset restricted what can be searched? What if instead of a search box there was another interface
or what if they told users not to look up things that they can find easily on Google? Why is it that new companies are expected to
improve on the algorithm that has ruled the web for over a decade? Instead, the expectation should really be to solve the
problems that can not be solved by Google today.
Conclusion
Semantic search is an upcoming technology that has set the expectations way too high.
We have all been misled into thinking that these technologies are here to dethrone Google by
delivering better search results. Neither of those things are true. What is true, however is that
semantic search is going to be big and it is going to help us answer questions that we
simply cannot answer today – complex, inferencing queries asked over the entire web as if it was a
database.
In order for these semantic search technologies to make a dent in the market, they need
to clean up their messaging and most importantly, their user interface. Presenting a search box is both
misleading and detrimental, as people associate it with the simplistic questions that Google solves
without any problems. To really showcase semantic search, these companies need to come up
with innovative UIs that will help users to understand the power that is being put at
their fingers.
As always, please tell us what you think. What should semantic search companies do to gain their place in the marketplace?