
One of the highlights of October’s Web 2.0 Summit in San Francisco was the emergence of ‘Semantic Apps’ as a force. Note that we’re not necessarily talking about the Semantic Web, which is the Tim Berners-Lee W3C led initiative that touts technologies like RDF, OWL and other standards for metadata. Semantic Apps may use those technologies, but not necessarily. This was a point made by the founder of one of the Semantic Apps listed below, Danny Hillis of Freebase (who is as much a tech legend as Berners-Lee).

The purpose of this post is to highlight 10 Semantic Apps. We’re not touting this as a ‘Top 10’, because there is no way to rank these apps at this point – many are still non-public apps, e.g. in private beta. It reflects the nascent status of this sector, even though people like Hillis and Spivack have been working on their apps for years now.
What is a Semantic App?
Firstly let’s define “Semantic App”. A key element is that the apps below all try to determine the meaning of text and other data, and then create connections for users. Another of the founders mentioned below, Nova Spivack of Twine, noted at the Summit that data portability and connectibility are keys to these new semantic apps – i.e. using the Web as platform.
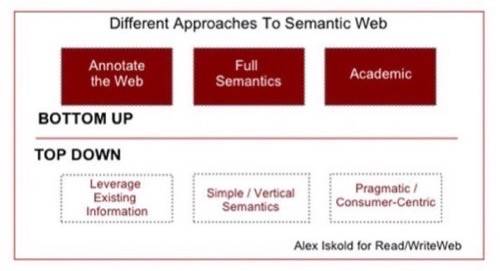
In September Alex Iskold wrote a great primer on this topic, called Top-Down: A New Approach to the Semantic Web. In that post, Alex Iskold explained that there are two main approaches to Semantic Apps:
1) Bottom Up – involves embedding
semantical annotations (meta-data) right into the data.
2) Top down –
relies on analyzing existing information; the ultimate
top-down solution would be a fully blown natural language processor, which is able to
understand text like people do.
Now that we know what Semantic Apps are, let’s take a look at some of the current leading (or promising) products…
Freebase
Freebase aims to “open up the silos of data and the connections between them”, according to founder Danny Hillis at the Web 2.0 Summit. Freebase is a database that has all kinds of data in it and an API. Because it’s an open database, anyone can enter new data in Freebase. An example page in the Freebase db looks pretty similar to a Wikipedia page. When you enter new data, the app can make suggestions about content. The topics in Freebase are organized by type, and you can connect pages with links, semantic tagging. So in summary, Freebase is all about shared data and what you can do with it.

Powerset
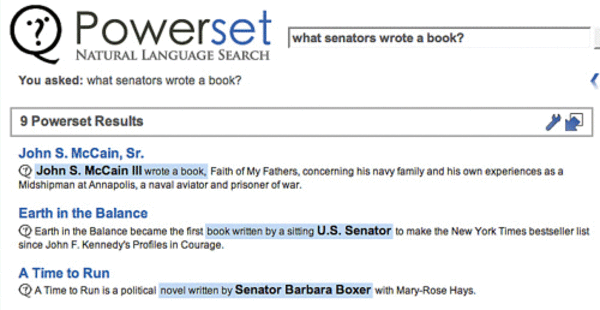
Powerset (see our coverage here and here) is a natural language search engine. The system relies on semantic technologies that have only become available in the last few years. It can make “semantic connections”, which helps make the semantic database. The idea is that meaning and knowledge gets extracted automatically from Powerset. The product isn’t yet public, but it has been riding a wave of publicity over 2007.
Twine
Twine claims to be the first mainstream Semantic Web app, although it is still in private beta. See our in-depth review. Twine automatically learns about you and your interests as you populate it with content – a “Semantic Graph”. When you put in new data, Twine picks out and tags certain content with semantic tags – e.g. the name of a person. An important point is that Twine creates new semantic and rich data. But it’s not all user-generated. They’ve also done machine learning against Wikipedia to ‘learn’ about new concepts. And they will eventually tie into services like Freebase. At the Web 2.0 Summit, founder Nova Spivack compared Twine to Google, saying it is a “bottom-up, user generated crawl of the Web”.

AdaptiveBlue
AdaptiveBlue are makers of the Firefox plugin, BlueOrganizer. They also recently launched a new version of their SmartLinks product, which allows web site publishers to add semantically charged links to their site. SmartLinks are browser ‘in-page overlays’ (similar to popups) that add additional contextual information to certain types of links, including links to books, movies, music, stocks, and wine. AdaptiveBlue supports a large list of top web sites, automatically recognizing and augmenting links to those properties.

SmartLinks works by understanding specific types of information (in this case links) and wrapping them with additional data. SmartLinks takes unstructured information and turns it into structured information by understanding a basic item on the web and adding semantics to it.
[Disclosure: AdaptiveBlue founder and CEO Alex Iskold is a regular RWW writer]
Hakia
Hakia is one of the more promising Alt Search Engines
around, with a focus on natural
language processing methods to try and deliver ‘meaningful’ search results. Hakia attempts to
analyze the concept of a search query, in particular by doing sentence
analysis. Most other major search engines, including Google, analyze keywords.
The company told us in a March interview that the future of search engines will go beyond keyword
analysis – search engines will talk back to you and in effect become your search
assistant. One point worth noting here is that, currently, Hakia has limited post-editing/human interaction for the editing of hakia Galleries, but the rest of the engine is 100% computer powered.

Hakia has two main technologies:
1) QDEX Infrastructure (which stands for Query Detection and Extraction) – this does the heavy lifting of analyzing search queries at a sentence level.
2) SemanticRank Algorithm – this is essentially the science they use, made up of ontological semantics that relate concepts to each other.
Talis
Talis is a 40-year old UK software company which has created a semantic web application platform. They are a bit different from the other 9 companies profiled here, as Talis has released a platform and not a single product. The Talis platform is kind of a mix between Web 2.0 and the Semantic Web, in that it enables developers to create apps that allow for sharing, remixing and re-using data. Talis believes that Open Data is a crucial component of the Web, yet there is also a need to license data in order to ensure its openness. Talis has developed its own content license, called the Talis Community License, and recently they funded some legal work around the Open Data Commons License.

According to Dr Paul Miller, Technology Evangelist at Talis, the company’s platform emphasizes “the importance of context, role, intention and attention in meaningfully tracking behaviour across the web.” To find out more about Talis, check out their regular podcasts – the most recent one features Kaila Colbin (an occassional AltSearchEngines correspondent) and Branton Kenton-Dau of VortexDNA.
UPDATE: Marshall Kirkpatrick published an interview with Dr Miller the day after this post. Check it out here.
TrueKnowledge
Venture funded UK semantic search engine TrueKnowledge unveiled a demo of its private beta earlier this month. It reminded Marshall Kirkpatrick of the still-unlaunched Powerset, but it’s also reminiscent of the very real Ask.com “smart answers”. TrueKnowledge combines natural language analysis, an internal knowledge base and external databases to offer immediate answers to various questions. Instead of just pointing you to web pages where the search engine believes it can find your answer, it will offer you an explicit answer and explain the reasoning patch by which that answer was arrived at. There’s also an interesting looking API at the center of the product. “Direct answers to humans and machine questions” is the company’s tagline.

Founder William Tunstall-Pedoe said he’s been working on the software for the past 10 years, really putting time into it since coming into initial funding in early 2005.
TripIt
Tripit is an app that manages your travel planning. Emre Sokullu reviewed it when it presented at TechCrunch40 in September. With TripIt, you forward incoming bookings to [email protected] and the system manages the rest.
Their patent pending “itinerator” technology is a baby step in the semantic web – it
extracts useful infomation from these mails and makes a well structured and
organized presentation of your travel plan. It pulls out information from Wikipedia for the places that you visit. It uses
microformats – the iCal format, which is well integrated into GCalendar and
other calendar software.

The company claimed at TC40 that “instead of dealing with 20 pages of planning, you just print out 3
pages and everything is done for you”. Their future plans include a recommendation engine which will tell you where to
go and who to meet.
Clear Forest

ClearForest is one of the companies in the top-down
camp. We profiled the product in December ’06 and at that point ClearForest was applying its core natural language
processing technology to facilitate next generation semantic applications. In April 2007 the company was acquired by Reuters. The company has both a Web Service and a Firefox extension that leverages an API
to deliver the end-user application.
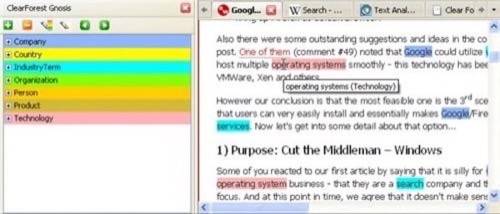
The Firefox extension is called Gnosis and it enables you to “identify the people, companies, organizations, geographies and products on the page you are viewing.” With one click from the menu, a webpage you view via Gnosis is filled with various types of annotations. For example it recognizes Companies, Countries, Industry Terms, Organizations, People, Products and Technologies. Each word that Gnosis recognizes, gets colored according to the category.
Also, ClearForest’s Semantic Web Service offers a SOAP interface for analyzing text, documents and web pages.
Spock
Spock is a people search engine that got a lot of buzz when it launched. Alex Iskold went so far as to call it “one of the best
vertical semantic search engines built so far.” According to Alex there are four things that makes their
approach special:

- The person-centric perspective of a query
- Rich set of attributes that characterize people (geography, birthday, occupation,
etc.) - Usage of tags as links or relationships between people
- Self-correcting mechanism via user feedback loop
As a vertical engine, Spock knows important attributes that people have: name, gender, age, occupation and location just to name a few. Perhaps the most interesting aspect of Spock is its usage of tags – all frequent phrases that Spock extracts via its crawler become tags; and also users can add tags. So Spock leverages a combination of automated tags and people power for tagging.
Conclusion
What have we missed? 😉 Please use the comments to list other Semantic Apps you know of. It’s an exciting sector right now, because Semantic Web and Web 2.0 technologies alike are being used to create new semantic applications. One gets the feeling we’re only at the beginning of this trend.









