











A few weeks ago, Werner Vogels, the CTO of Amazon, published a long technical paper on his blog about
Amazon’s highly available storage system called Dynamo. The paper itself is quite complex and technical and includes a description of the architecture,
algorithms and tests that Amazon has been doing with the system.

Yet, even from a casual glance, it is clear that Amazon’s work is very important. Since early last year,
the e-commerce giant has been making forays into becoming a Web OS company. Amazon has been methodically exposing pieces of its own infrastructure as commodity web
services, and in the process confusing Wall Street analysts and
making thousands of startups quite happy.
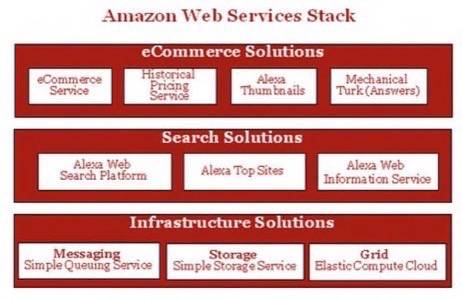
Dr. Vogels has been both the architect and the evangelist of this effort. In his speech at last year’s ETech conference
he explained that by leveraging the Amazon Web Services Stack, web developers are finally able to focus on the core business logic of their apps and services.
Hiding the enormous complexity of building a scalable web business behind a simple API, Amazon is paving the way toward a whole
new web ballgame.
What Vogels talked about on his blog a few weeks back is not a public web service, but a piece of internal infrastructure,
which allows Amazon to service millions of customers. The paper is a unique revelation about the inner workings of
one of just a handful of Internet giants. It is also a preview of the web services to come in the next decade. In this post
we take a close look at Dynamo, discuss where it fits and consider its implications.
Scalability Issues With Relational Databases
Before discussing Dynamo it is worth taking look back to understand its origins. One of the most powerful
and useful technologies that has been powering the web since its early days is the relational database.
Particularly, relational databases have been used a lot for retail sites where visitors are able to browse and search for products.
Modern relational database are able to handle millions of products and service very large sites.
However, it is difficult to create redundancy and parallelism with relational databases, so
they become a single point of failure. In particular, replication is not trivial. To understand why, consider
the problem of having two database servers that need to have identical data. Having both servers for reading and writing
data makes it difficult to synchronize changes. Having one master server and another slave is bad too, because the master has to
take all the heat when users are writing information.
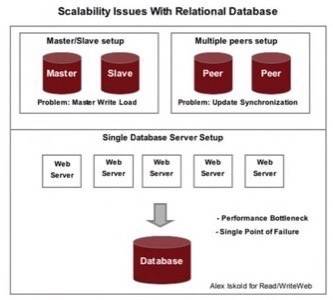
So as a relational database grows, it becomes a bottle neck and the point of failure for the entire system.
As mega e-commerce sites grew over the past decade they became aware of this issue – adding more web servers does not help because it is the database
that ends up being a problem.
Dynamo – A Distributed Storage System
Unlike a relational database, Dynamo is a distributed storage system. Like a relational database it is stores information
to be retrieved, but it does not break the data into tables. Instead all objects are stored and looked up via a key.
A simple way to think about such a system is in terms of URLs. When you navigate to the page on Amazon for the last
Harry Potter book, http://www.amazon.com/gp/product/0545010225 you see a page that includes a
description of the book, customer reviews, related books, and so on. To create this page, Amazon’s infrastructure
has to perform many database lookups, the most basic of which is to grab information about the book from its URL
(or, more likely, from its ASIN – a unique code for each Amazon product, 0545010225 in this case).
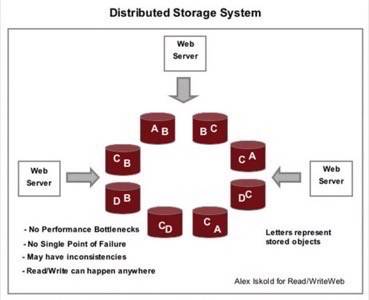
In the figure above we show a concept schematic for how a distributed storage system works.
The information is distributed around a ring of computers, each computer is identical. To ensure fault tolerance, in case
a particular node breaks down, the data is made redundant, so each object is stored in the system multiple times.
In technical terms, Dynamo is called an eventually consistent storage system. The terminology
may seem a bit odd, but as it turns out creating a distributed storage solution which is both responsive
and consistent is a difficult problem. As you can tell from the diagram above, if one computer updates object A,
these changes need to propagate to other machines. This is done using asynchronous communication, which is why
the system is called “eventually consistent.”
How Dynamo Works
The technical details in Vogels’ paper are quite complex, but the way in which Dynamo works can be understood more simply.
First, like Amazon S3, Dynamo offers a simple put and get interface. Each put
requires the key, context and the object. The context is based on the object and is used by Dynamo
for validating updates. Here is the high level description of Dynamo and a put request:
- Physical nodes are thought of as identical and organized into a ring.
- Virtual nodes are created by the system and mapped onto physical nodes, so that hardware
can be swapped for maintenance and failure. - The partitioning algorithm is one of the most complicated pieces of the system, it specifies which nodes will store
a given object. - The partitioning mechanism automatically scales as nodes enter and leave the system.
- Every object is asynchronously replicated to N nodes.
- The updates to the system occur asynchronously and may result in multiple copies of the object in the system with slightly
different states. - The discrepancies in the system are reconciled after a period of time, ensuring eventual consistency.
- Any node in the system can be issued a put or get request for any key.
So Dynamo is quite complex, but is also conceptually simple. It is inspired by the way things work in nature – based on
self-organization and emergence. Each node is identical to other nodes, the nodes can come in and out of existence, and the data is automatically
balanced around the ring – all of this makes Dynamo similar to an ant colony or beehive.
Finally, Dynamo’s internals are implemented in Java. The choice is likely because, as we’ve written here,
Java is an elegant programming language, which allows the appropriate level of object-orineted modeling. And yes, once again, it is fast enough!
Dynamo – The SLA In A Box
Perhaps the most stunning revelation about Dynamo is that it can be tuned using just a handful parameters to achieve
different, technical goals that in turn support different business requirements. Dynamo is a storage service in the box driven by an SLA.
Different applications at Amazon use different configurations of Dynamo depending on their tolerence to delays or data discrepancy.
The paper lists these main uses of Dynamo:
Business logic specific reconciliation: This is a popular use case for Dynamo. Each data object is replicated across multiple nodes. The shopping cart service is a prime example of this category.
Timestamp based reconciliation: This case differs from the previous one only in the reconciliation mechanism. The service that maintains customers’ session information is a good example of a service that uses this mode.
High performance read engine: While Dynamo is built to be an “always writeable” data store, a few services are tuning its quorum characteristics and using it as a high performance read engine. Services that maintain a product catalog and promotional items fit in this category.
Dynamo shows once again how disciplined and rare Amazon is at using and re-using its infrastructure. The technical management
must have realized early on that the very survival of the business depended on common, bullet proof, flexible, and scalable software systems.
Amazon succeeded in both implementing and spreading the infrastructure through the company. It truly earned the mandate to then
leverage its internal pieces and offer them as web services.
How Does Dynamo Fit With AWS?
The short answer is that it does not, because it is not a public service. The short answer is also shortsighted because
there are clear implications. First, is that since Amazon is committed to building a stack of web services, a version of Dynamo
is likely to be available to the public at some time in the future.
Second, Amazon is restless in its innovation; and that applies to web services as well as it applies to its retail business. S3 has already made possible a whole new generation
of startups and web services and Dynamo is likely to do the same when it comes out. And we know that more is likely to come, as even with
Dynamo, the stack of web services is far from complete.
Finally, Amazon is showing openness – a highly valuable characteristic. Surely, Google and Microsoft
have similar systems, but Amazon is putting them out in the open and turning its infrastructure into a business faster
than its competitors. It is this openness that will allow Amazon to build trust and community around their Web Services stack. It is a powerful force, which is likely to win over developers and business people as well.
The Future – Amazon Web OS
To any computer scientist or software engineer to watch what Amazon is doing is both awesome and humbling.
Taking complex theoretical concepts and algorithms, adopting them to business environments (down to the SLA!), proving
that they work at the world’s largest retail site, and then turning around and making them available to the rest of the world
is nothing short of a tour-de-force. What Emre Sokullu called HaaS (Hardware as a Service) in his post
yesterday is not only an innovative business strategy, but also a triumph of software engineering.
Amazon is on track to roll out more virtual web services, which will collectively amount to a web operating system.
The building blocks that are already in place and the ones to come are going to be remixed to create new web applications
that were simply not possible before. As we have written here recently, it is the libraries that make it possible to create giant systems
with just a handful of engineers. Amazon’s Web Services are going to make web-scale computing available to anyone. This is
unimaginably powerful. This future is almost here, so we can begin thinking about it today. What kinds of things do you want to build
with existing and coming Amazon Web Services?




















