
Summary: The original vision of the semantic web as a layer on top of the current web, annotated in a way that computers can “understand,” is certainly grandiose and intriguing. Yet, for the past decade it has been a kind of academic exercise rather than a practical technology. This article explores why; and what we can do about it. Update: Part 2 is available nowTop-Down: A New Approach to the Semantic Web
The semantic web is a vision pioneered by Sir Tim Berners-Lee, in which information is expressed
in a language understood by computers. In essence, it is a layer on top of the current web that describes concepts and relationships, following strict rules of logic.
The purpose
of the semantic web is to enable computers to “understand” semantics the way humans do. Equipped
with this “understanding,” computers will theoretically be able solve problems that are out of reach today.
For example, in a New York Times article,
written earlier this year, John Markoff discussed a scenario where you would be able to ask a computer
to find you a low budget vacation, keeping in mind that you have a 3 year old child. Primitively speaking,
because the computer would have a concept of travel, budget and kids, it would be able to find the ideal
solution by crawling the semantic web in much the same way Google crawls the regular web today.
But while the vision of a semantic web is powerful, it has been a over a decade in making. A lot of
work has been done at the World Wide Web Consortium (W3C) specifying the pieces needed to put it together. Yet, for reasons ranging from
conceptual difficulties to lack of consumer focus, the semantic web as originally envisioned remains elusive.
In this post, we take a deeper look at the issues and wonder if the classic bottom-up approach can ever work.
Classic Semantic Web Review
In our post earlier this year, The Road to the Semantic Web,
we discussed the elements of the classic semantic web approach. In a nutshell, the idea is to represent information using mathematical graphs
and logic in a way that can be processed by computers. To express meaning, the classic semantic web approach also advocates
the creation of ontologies, which describe hierarchical relationships between things.
For example, using such ontologies it would
be possible to express truths like: dog is a type of animal or Honda Civic is a type of car.
It would then also be possible to describe the relationships between things like this: dog is eating food and
John is drivng a Honda Civic. By combining entities and relationships and expressing all content on the web in such a way,
the result would be a giant network, or, the semantic web.
The W3C has mapped out a set of tools and standards that are needed to make it happen, two of which are the XML-based languages
RDF and OWL that are designed to be flexible and powerful. To accommodate for the distributed nature of semantic web, documents
are made self-describing – the meta data (meaning) is embedded in the document itself. The entire stack, as it was
envisioned by Sir Tim Berners-Lee, was presented in 2000 (see image below), the rest of the post will focus on the
difficulties with this approach.
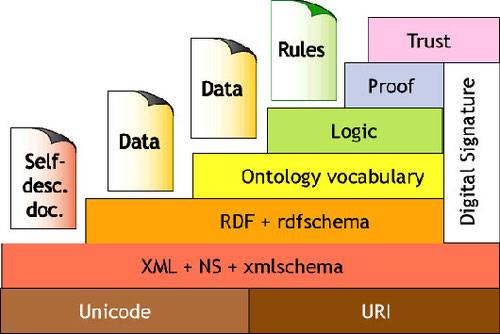
The Technical Challenges
1. Representational Complexity: The first problem is that RDF and OWL are complicated. Even for scientists and mathematicians these graph-based
languages take time to learn and for less-technical people they are nearly impossible to understand. Because
the designers were shooting for flexibility and completeness, the end result are documents that are confusing,
verbose and difficult to analyze.
2. The Natural Language Problem: People argue that RDF and OWL are for machines only, so it does not matter that people
might find them hard to look at. (Though as a side note, the advantage of XML representation is precisely that people can look at it, mainly for debugging purposes.) But even assuming that RDF and OWL are for machines
only, the question arises: how are these documents to be created?
There are two possible ways, one is automated, where an algorithm takes a piece of text and
produces RDF, another approach is for people to annotate existing documents using visual tools that then generate RDF from those annotations. Both approaches have problems. If there is already an algorithm that can take a piece of
text and generate RDF, then this algorithm should be smart and AI-like. Why do we even need the RDF if
we already have such an algorithm? The issue with manually annotating documents is exactly that: it is manual.
Having people annotate things for computers to process is at the least inefficient and at the most offensive.
3. The Bottom-Up Assumption: Because there are vast amounts of existing information that need to be transformed, the classic semantic web
approach is a bottom-up approach. Annotating information on the web-scale is a daunting task. If it is to be done
be a centralized entity, then there will need to be Google-like semantic web crawler that takes pages and transforms them
into RDF. This comes back to the issue we just discussed – having an automatic algorithm that infers meaning from
text the way humans do. Creating such an algorithm may not be possible at all (and again begs the question of the need for RDF if the algorithm exists).

An alternative is to have web sites themselves generate and maintain meta data. While this is certainly
a much more scalable approach it raises questions. First, what benefit is there for web sites to do this?
Second, what tools are out there to get it done? Assuming that these questions are answered
this would be the more viable alternative.
4. The Standards Issue: A distributed or self-organizing approach to the problem seems the most promising, but it runs into
the classic technology issue of standards or the even more ancient human problem of common language.
The history of technology is full of Tower of Babel examples – separate distributed systems that
do not talk to each other. A common solution is to build an adapter or translator that
maps concepts from one system to another.
For example, suppose there are representations of a book defined by Barnes and Noble and Amazon.
Each has common fields like ISBN and Author, but there maybe subtle differences, i.e., one of them may
define edition like this: 1st edition and the other like this: edition 1. This seemingly minor
difference, one that people would not even think twice about, would wreak havoc in computers.

The only way to have interoperability is to define a common standard for how to describe a book.
So having self-describing documents is not enough, because there still needs to be a literal syntactic
agreement in order for computer systems to interoperate. The bottom line is that there needs to be
a standard and an API.
The Scientific Challenges
1. The Godel and NP-completeness: The technical issues seem to be steep, but even if these issues are addressed there are much
deeper and more fundamental problems. A famous mathematical system proved by Kurt Godel in 1933 states: No logical system can ever
be both consistent and complete, which means that there are things that can not be proved by logic. That essentially means that not all problems can be solved.
Godel’s work was extended by British mathematician Alan Turing and later led to modern computational complexity theory.
There is a class of problems, known as NP-complete, that basically can not be solved efficiently by a modern computer.
The reason is that the solutions are not algorithmic and requires exploration of all possible paths.
2. Dealing with Uncertainty: You may not understand Godel or NP-completeness,
but you are familiar with the consequence – living with uncertainty. Uncertainty is something that computers can’t deal with but that we can handle very well. In fact, we thrive on it.
Everyday we make decisions without knowing all the facts. We do this by utilizing iteration.

Here is a simple example of how we get around uncertainty: When someone speaks to us and we don’t
understand, we say: Excuse me, but what do you mean? After the person explains what they’re trying to communicate using slightly different
words we typically get it. But this is something that computers built on principles of the classic semantic web
would not be able to do. They require infallible logic. They require precise representation of the facts.
This is certainly not true in our lives, and it is unlikely to be possible on the web.
3. Replacing Humans With Machines: Going back to John Markoff’s example of a computer booking a perfect vacation, one can’t help
but think of a travel agency. In the good old days, you would go to the same agent over and over again.
Why? Because just like your friends, your doctor, your teacher, the travel agent needs to know you personally
to be able to serve you better.

The travel agent remembers that you’ve been to Prague and Paris, which is why he offers
you a trip to Rome. The travel agent remembers that you’re a vegetarian and orders the pasta meal for you on your flight. Over time people learn and memorize facts about life and each other.
Until machines can do the same, knowledge of semantics, limited or full is not going to be enough to replace humans.
The Business Challenges
Perhaps the worst challenge facing the semantic web is the business challenge. What is the consumer value?
How is it to be marketed? What business can be built on top of the semantic web that can not exist today?
Clearly the example of instant travel match is not a “wow.” It’s primitive and, in a way, uninteresting because
many of us are already quite adept at being our own travel agent using existing tools. But assuming that there
are problems that can be solved faster, there is still a question of specific end user utility.
The way the semantic web is presented today makes it very difficult to market. The “we are
a semantic web company” slogan is likely to raise eyebrows and questions. RDF and OWL clearly need to be
kept under the hood. So the challenge is to formulate the end user value in ways that will resonate with people.
This is particularly important, if the bottom-up approach is to work. If people can see the value, then so will
businesses and that might prompt them to start annotating and transforming their information. Yet,
it’s difficult to see how this will happen, given the current, rather academic focus.
Conclusion
The original vision of the semantic web as a layer on top of the current web, annotated in a way that computers can
“understand,” is certainly grandiose and intriguing. Yet, for the past decade it has been a kind of academic
exercise rather than a practical technology. The technical, scientific and business difficulties are substantial, and to overcome them, there needs to be more community support, standards and pushing. This is not likely to happen
unless there are more clear reasons for it.
We will discuss an alternative approach that we call the Top-Down Semantic Web in our next article.
Please tell us what you think about the prospects for the classic semantic web approach in the comments below.
Update: Part 2 is available nowTop-Down: A New Approach to the Semantic Web









