
This post is a result of an email exchange between Greg Pass from Summize and myself (Alex Iskold). Big thanks to Greg
for his original ideas and the technical collaboration.
We spend most of our time online searching for information. This is not
surprising, since the Web is a vast sea of information, where finding exactly what you
are looking for is not easy. But why is it that when we find something on one site it is
still not easy to find it on another? Say you found a Harry Potter book on Barnes and
Noble, why is it still hard to find the same item on other sites like Amazon and Powells?
Why is search a one time deal?

We are used to a Web where each site has its own copy of the information. Each web
site is a silo. But that does not need to be the case. If web sites agree on how to
represent things like books, music, movies, travel destinations and gadgets, then we
would spend a lot less time searching. Imagine that the URL for the Harry Potter Goblet
of Fire book is this:
http://www.amazon.com/books/j-k-rowling/harry-potter-and-the-goblet-of-fire
In other words, if there was a standard way to turn things into URLs, then finding
information would be a lot easier.
Standard URLs – Web Sites as Directories
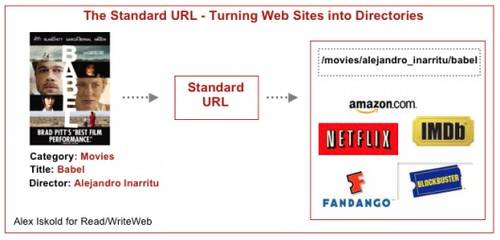
The basic idea behind standard URLs is simple – given a type of object, like a book or
a movie or a music album, create a URL schema that can be used by any site. Here are some
basic examples to get us started:
- /books/michael-pollan/the-omnivores-dilemma-a-natural-history-of-four-meals
- /music/jack-johnson/in-between-dreams
- /movies/alejandro-inarritu/babel
First, the objects are divided into categories such as books, music and movies. The
category is followed by a major attribute such as author, artist or director. Finally
there is the title of the object. So for example, if this scheme worked, we could type
in:
http://www.netflix.com/movies/alejandro-inarritu/babel
…to get to that movie on Netflix. Or:
http://www.blockbuster.com/movies/alejandro-inarritu/babel
…to get to the movie on Blockbuster.com.
There are three big benefits to standard URLs:
- Savvy web users can just type in URLs directly, using this naming convention.
- Search engines will deliver more precise results.
- Most importantly, any site can automatically link to the same object on another site,
saving people a ton of search time.
Extending the idea of standard URLs, we can think of web sites as directories. For
example, /books should match all books, while
/books/michael-pollan should match all books by Michael Pollan. So in a
way, instead of a search, users will be doing a directory listing – which is much more
reliable. If this works, the next step would be auto-completion as the user keys in the
URL. It would work by having the browser query the list of possible matches from the web
site. However doing auto-complete on URLs would be more harder than doing auto complete
on Google search today.
Who is working on this?
Quite a few companies are doing this already. del.icio.us was one of the first
companies to start using standard URLs. However, del.icio.us does this only for tags. So a URL like
http://del.icio.us/tags/books returns all posts tagged with
books. A richer example is the review aggregator called Metacritic, which we covered here.
Metacritic developed proprietary representations for objects, similar to the one we
discussed above. For example, here is a link to a music album:
http://www.metacritic.com/music/artists/arcadefire/neonbible
Amazon is also trying to do this, but it seems like there are legacy issues that
prevent the eCommerce giant from fully implementing standard URLs. The example below
shows that there is still the need to have an ASIN (universal identifier for all Amazon
products) as part of the URL:
http://www.amazon.com/Songs-About-Jane-Maroon-5/dp/B00006879E
Possible protocol
The actual nuances of the protocol are not really that important. To paraphrase Dave Winer, it does not matter what the standard is, as
long as there is a standard. This is a really important observation, as a lot of times we
argue over the details – forgetting that there is an important bigger goal that we are
trying to get to. Greg and I discussed specific, fairly simple flavors of the possible
protocol. The main idea is to represent objects like this:
/topic/major-attribute/title/[one or more minor attributes]
Each object needs to be presented so that it is as distinct as possible. The
disambiguation is done by adding one or more minor attributes after the title. For
example, for a book a minor attribute could be a type – softcover or hardcover. It is
important to agree on the sequence of the minor attributes for each topic. For example,
for music it could be year, followed by record label followed by genre.
Difficulties with standard URLs
No matter what the specifics are, it is unlikely that a protocol will be able to
eliminate ambiguity completely. That is ok, as long as it works most of the time – the
benefits will be greater than the glitches. In the worst case scenario, users will see
all matching objects instead of exactly one. That is, in the worst case scenario we are
back to search – except that it would be much more precise, since it would actually be a
directory listing.
Conclusion
Can this actually work? Yes, but it will take a big community effort. Adopting a
standard on a web-scale is no easy endeavor, but this one could be worth considering.
There is a big incentive for the companies as well – they want users to get to their
content as quickly as possible.
Let us know what do you think about this idea.









