Written by Alex Iskold
Earlier this week we wrote about The Race to beat Google. In that article we discussed various approaches that startups are taking trying to unseat the web giant. In this post we are going to zoom in on one of the companies – Clusty and their search clustering technology. Before looking at the specifics of Clusty, we will discuss the issues with search at large and will give an overview of clustering.

What is perfect search?
It is interesting to ask: What do we expect when we enter a term into a search box? Ideally, we’d like to get the perfect answer right away. Often, we have an idea what that perfect answer should be, and when computer does not get it for us we are disappointed. But are we being reasonable? Can we expect the “perfect” answer all the time?
Consider for example, our interactions with an Information clerk at the mall. When we ask for a location of a store, she may or may not give us the “perfect” answer. She might not know where this store is, she might not understand us or we may not understand what she said. So for many reasons we may not get the “perfect” answer right away.
What is qualitatively different between our experience with the Information clerk vs. a search engine is that
with the clerk we have a dialog. When she does not understand what we asked, she has a chance,
to say Excuse me, what do you mean?. Google does not do that, it just gives us the results. If we do not like the answer we have to start from scratch.
The problem is that human interactions are fundamentally iterative, while our interactions with computers are
mostly stateless. Perhaps we could get to the perfect search results if we could have a dialog with the computer? Clustering technologies, particularly the one offered by Clusty, give computer a chance to clarify:
Excuse me, when you searched for Alex Iskold, did you mean to look for Read/Write Web or AdaptiveBlue or perhaps you where looking for static analysis tools that Alex worked on while at IBM?.
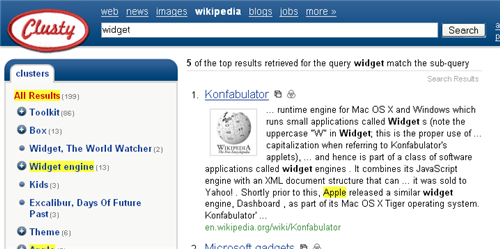
What is clustering?
Clusters are very common phenomenon both in nature and in human society. The examples of clusters include
cities, galaxies, a family and of course web sites focused on a similar topic. At its core, clustering is simply a
similarity grouping. A good visual way to think about clustering web sites is by picturing a network, like the one shown below.
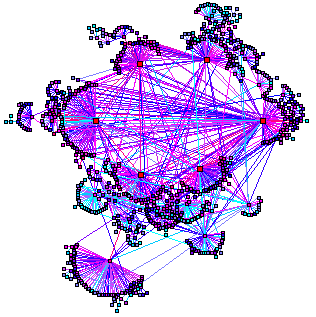
The image above is from Bradley Huffaker Research
There are many clustering techniques and certainly the exact ones used by Clusty or other search engines are a secret. Here is however, a simplistic view of how clustering works. Each web page is run through a statistical frequency analyzer, that outputs a list of most commonly occurring words and phrases. Each word and phrase then becomes a node in the network.
When two words occur in the same document, the link between them is formed. If the two words co-occur again, the weight of the link between them increased. This processed is repeated iteratively with billions of web pages.
The result is a network, or more mathematically speaking, a weighted graph. Since some words gravitate to each other more – this weighted graph will be clustered.
The Basic Web Search with Clusty
It is remarkable that the clusters formed in this way capture meaning. For example, pages where Alex Iskold
is the founder of AdaptiveBlue will be distinct from the pages where Alex Iskold is described as a Read/WriteWeb contributor. Clusty takes advantage of this and uses clusters to refine the search. Every time when we perform a search, Clusty pulls together the data from other engines like Ask, MSN and Wisenut. It then organizes the search results in a way that helps us navigates away from ambiguity towards specific cluster of results:
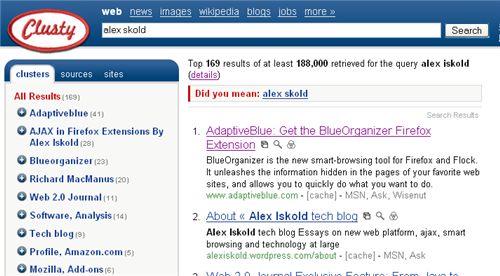
The clusters appear in the left navigation bar while the main results are shown in the center section. The clustering performed by Clusty is hierarchical, so within each cluster there are sub-clusters that user can drill into. This is a good idea because it allows the user to further refine the results. As the user clicks on the link the results in the main section reload. All this is great and positive about Clusty, but there are also things that need to be improved.
First, the names of the clusters need to be normalized. For example, when I drill into AdaptiveBlue, under the
results for Alex Iskold, I get:
- Demo
- Interview, CTO
- Alex Iskold is the founder and CEO of AdaptiveBlue
- Tagged, Technorati
- etc.
which is not intuitive. This may not be an easy thing to fix, but as is, its just very difficult to understand. Another issue is rather cosmetic, but it also has a negative impact on the user experience. Pages reload every time when the user clicks on a cluster link, using Ajax here would make experience much more pleasant.
Beyond the basic search
Clusty technology is generic, since the allows the user to perform vertical search for Blogs, Images, News, Jobs and Wikipedia. In addition to the same representation of results they all have the feature called Find in a cluster. This essentially is a secondary search, which allows the user to slice the results by another criteria.
I particularly like the implementation here, which highlights the matching clusters:
Another thing that we found interesting is the application of clustering to building tag clouds. In 2006 we saw a lot of sites offering tag clouds to help users navigate through popular topics. Clusty applied their technology to generating the cloud that can be used on any site:

Does Clusty have traction?
Clusty’s technology is certainly interesting, but is it popular? The company has been around for a while, but has not really been able to sway away people from Google. Clusty’s Alexa rank is slightly above 5,000 now, but a quick comparison with Snap over the last year does not point to a bright future:
Conclusion
So what do we make of this company and the clustering approach overall? We think that the approach has a potential if done well and Clusty is on the right track. The idea of being able to “have a dialog” with a computer by drilling into a subset of results is a good idea. However, the current implementation of Clusty needs to be perfected and polished before people will be willing to spend more time with it. So in principle this can work, but Vivisimo, the company behind Clusty, needs to figure how to make it flawless.